实用篇包含微服务治理(注册发现,远程调用,配置管理,网关路由)、Docker技术、异步通信、分布式缓存、分布式搜索
小简从 0 开始学 Java 知识之 Java-学习路线 中的《SpringCloud-实用篇》,不定期更新所学笔记,期待一年后的蜕变吧!<有同样想法的小伙伴,可以联系我一起交流学习哦!>
- 🚩时间安排:预计10天更新完
- 🎯开始时间:09-20
- 🎉结束时间:09-30
- 🍀总结:
 |
|---|
 |
1.微服务
①架构对比
架构 |
单体架构 |
分布式架构 |
|---|---|---|
描述 |
将业务的所有功能集中在一个项目中开发,打成一个包部署。 | 根据业务功能对系统做拆分,每个业务功能模块作为独立项目开发。 |
图示 |
 |
 |
优点 |
架构简单、部署成本低 | 降低服务耦合、有利于服务升级和拓展 |
缺点 |
耦合度高(维护困难、升级困难) | 服务调用关系错综复杂 |
分布式架构虽然降低了服务耦合,但是服务拆分时也有很多问题需要思考:
- 服务拆分的粒度如何界定?
- 服务集群地址如何维护?
- 服务的调用关系如何管理?
- 服务健康状态如何感知?
人们需要制定一套行之有效的标准来约束分布式架构。因此微服务来啦!!!
②微服务简介
微服务的架构特征:
- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责
- 自治:团队独立、技术独立、数据独立,独立部署和交付
- 面向服务:服务提供统一标准的接口,与语言和技术无关
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
微服务的上述特性其实是在给分布式架构制定一个标准,进一步降低服务之间的耦合度,提供服务的独立性和灵活性。做到高内聚,低耦合。因此微服务是一种经过良好架构设计的分布式架构方案 。

但方案该怎么落地?选用什么样的技术栈?其中在Java领域最引人注目的就是SpringCloud提供的方案了。
③微服务方案
目前国内使用最广泛的微服务方案:Dubbo、SpringCloud、SpringCloudAlibaba


⑤案例引入
下方的讲解都基于此案例进行,请提前搭建好此项目。项目cloud-demo 密码:1399
搭建方式:1.使用IDEA 打开 cloud-demo项目 2.创建两个数据库
cloud_order和cloud_user3.将提供的cloud-order.sql和cloud-user.sql导入对应库中 4.修改项目中数据库密码
项目结构:
cloud-demo # 父工程,管理依赖
├── order-service # 订单微服务,负责订单相关业务
└── user-service # 用户微服务,负责用户相关业务
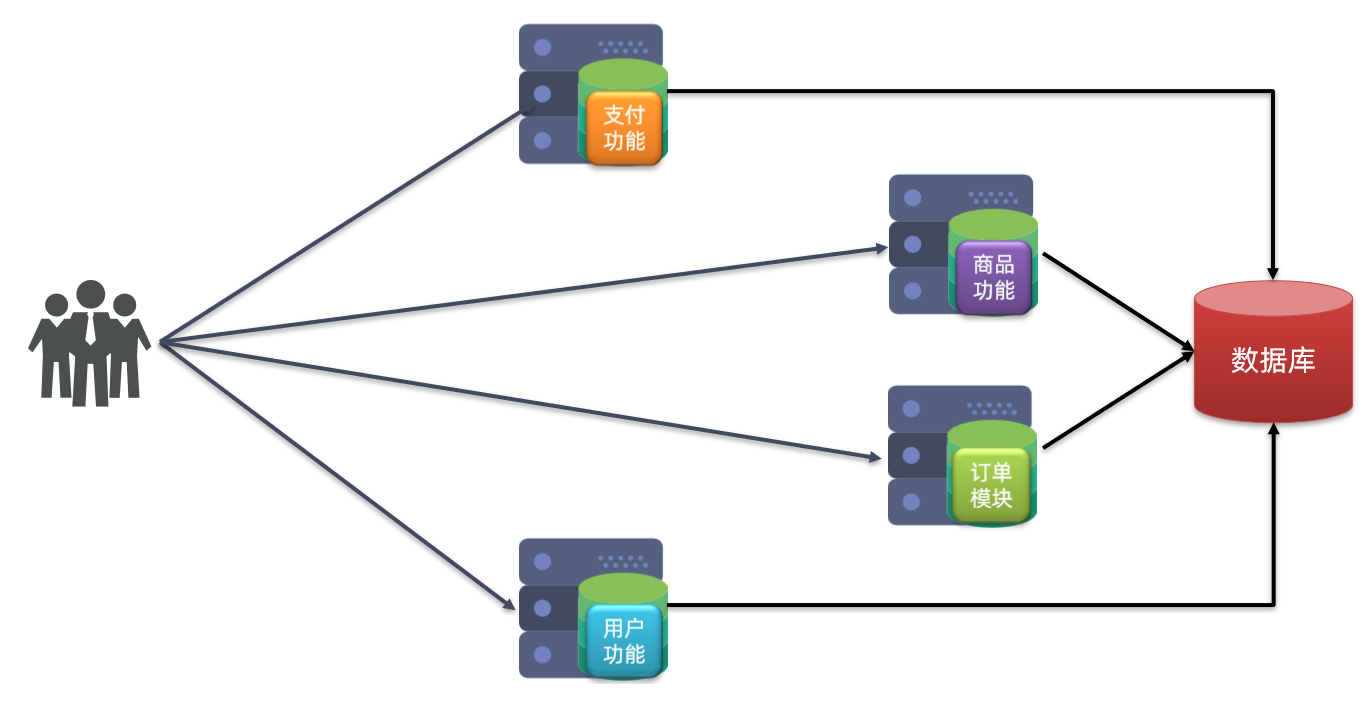
项目特征:
- 订单微服务和用户微服务有各自的数据库,相互独立
- 订单服务和用户服务都对外暴露Restful的接口
- 订单服务如果需要查询用户信息,只能调用用户服务的Restful接口,不能查询用户数据库
基础概念:
在服务调用关系中,会有两个不同的角色:
服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务)
服务消费者:一次业务中,调用其它微服务的服务。(调用其它微服务提供的接口)
服务提供者与服务消费者的角色并不是绝对的,而是相对于业务而言。

目前需求:修改order-service中的查询订单业务,要求在查询订单的同时,根据订单中包含的userId查询出用户信息,一起返回。

2.服务远程调用①
①RestTemplate
要实现上方需求,我们需要在order-service中向user-service发起一个http的请求,调用http://localhost:8081/user/{userId}接口。
步骤如下:
- 注册一个RestTemplate的实例到Spring容器
- 修改order-service服务中的OrderService类中的queryOrderById方法,根据Order对象中的userId查询User
- 将查询的User填充到Order对象,一起返回
步骤一:注册RestTemplate
@MapperScan("cn.xxxx.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
步骤二:实现远程调用
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.远程查询user
// 2.1 url地址
String url = "http://localhost:8081/user/" + order.getUserId();
// 2.2 发起调用
User user = restTemplate.getForObject(url, User.class);
// 3.存入order
order.setUser(user);
// 4.返回
return order;
}
}
3.服务注册发现
①Eureka
假如我们的服务提供者user-service部署了多个实例,如图:

思考几个问题:
- order-service在发起远程调用的时候,该如何得知user-service实例的ip地址和端口?
- 有多个user-service实例地址,order-service调用时该如何选择?
- order-service如何得知某个user-service实例是否依然健康,是不是已经宕机?
❶Eureka原理分析
这些问题都需要利用SpringCloud中的注册中心来解决,其中最广为人知的注册中心就是Eureka,其结构如下:

问题1:order-service如何得知user-service实例地址?
- user-service服务实例启动后,将自己的信息注册到eureka-server(Eureka服务端)。这个叫服务注册
- eureka-server保存服务名称到服务实例地址列表的映射关系
- order-service根据服务名称,拉取实例地址列表。这个叫服务发现或服务拉取
问题2:order-service如何从多个user-service实例中选择具体的实例?
- order-service从实例列表中利用负载均衡算法选中一个实例地址
- 并向该实例地址发起远程调用
问题3:order-service如何得知某个user-service实例是否依然健康,是不是已经宕机?
- user-service会每隔一段时间(默认30秒)向eureka-server发起请求,报告自己状态,称为心跳
- 当超过一定时间没有发送心跳时,eureka-server会认为微服务实例故障,将该实例从服务列表中剔除
- order-service拉取服务时,就能将故障实例排除了

❷搭建eureka-server
步骤一:创建eureka-server模块
在cloud-demo父工程下,创建一个maven子模块 eureka-server
步骤二:引入eureka依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
步骤三:编写启动类
编写一个启动类,添加@EnableEurekaServer注解,开启eureka的注册中心功能
@EnableEurekaServer
@SpringBootApplication
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}
步骤四:编写配置文件
server:
port: 10086
spring:
application:
name: eureka-server
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
步骤五:启动服务
启动微服务,然后在浏览器访问:http://127.0.0.1:10086,看到Web页面表示成功了
❸服务注册
下面,我们将user-service注册到eureka-server中去。
步骤一:引入依赖
在user-service的pom文件中,引入eureka-client依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
步骤二:配置文件
在user-service中,修改application.yml文件,添加服务名称、eureka地址:
spring:
application:
name: userservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
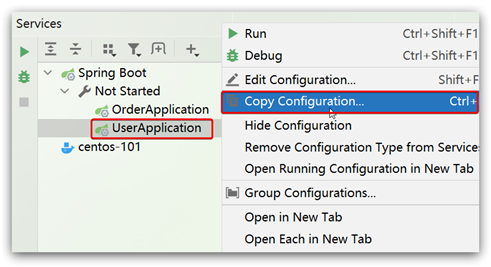
步骤三:启动多个user-service实例
为了演示一个服务有多个实例的场景,可以通过SpringBoot的启动配置,再启动一个user-service。
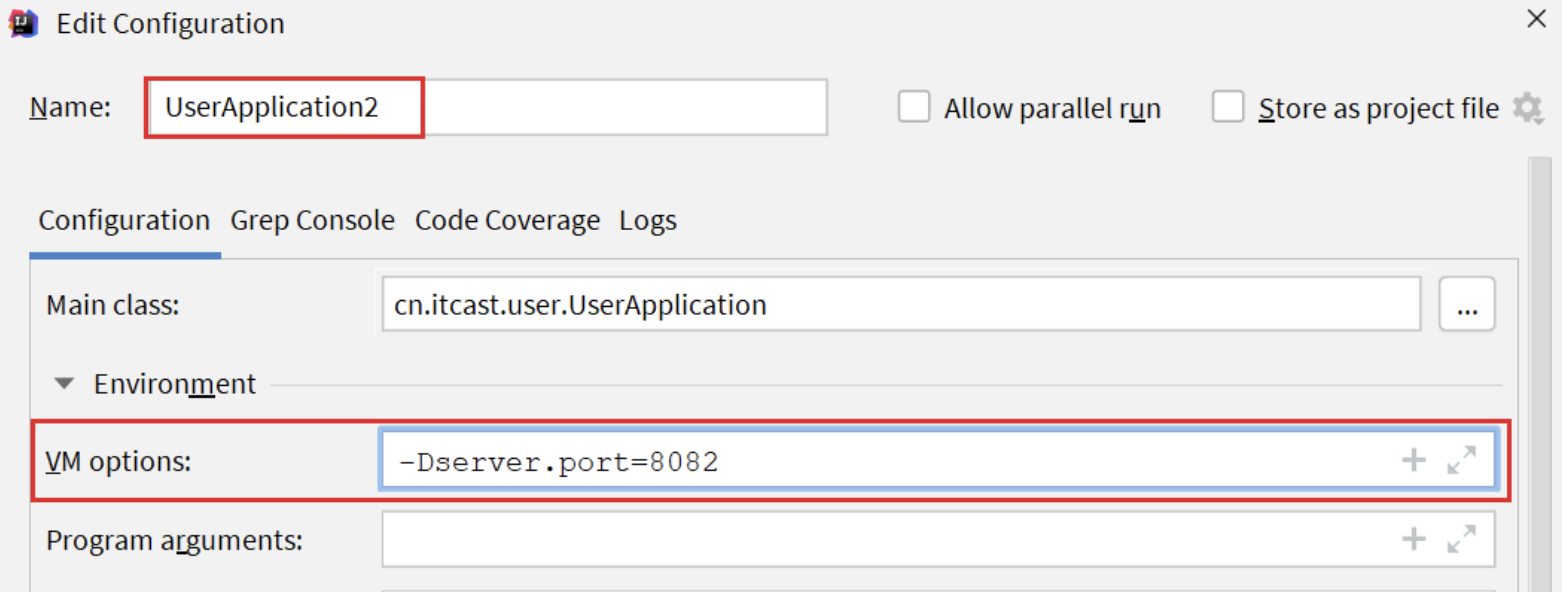
| 1.复制原来的user-service启动配置: | 2.在弹出的窗口中,填写信息: |
|---|---|
 |
 |
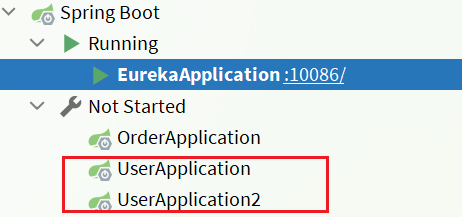
| 3.出现两个user-service实例 | 4.启动两个user-service实例 |
 |
 |
查看eureka-server管理页面:

❹服务发现
下面,我们将order-service的逻辑修改:实现向eureka-server拉取user-service的信息,即服务发现。
步骤一:引入依赖
服务发现、服务注册统一都封装在eureka-client依赖,因此这一步与服务注册时一致。
在order-service的pom文件中,引入eureka-client依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
步骤二:配置文件
服务发现也需要知道eureka地址,在order-service中,修改application.yml文件,添加服务名称、eureka地址:
spring:
application:
name: orderservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
步骤三:服务拉取和负载均衡
最后,我们要去eureka-server中拉取user-service服务的实例列表,并且实现负载均衡。
在order-service的OrderApplication中,给RestTemplate这个Bean添加一个@LoadBalanced注解:
@MapperScan("cn.xxxx.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
@Bean
@LoadBalanced //添加注解
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
修改order-service服务中的OrderService类中的queryOrderById方法。修改访问的url路径,用服务名代替ip、端口:
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.远程查询user
// 2.1 url地址
//String url = "http://localhost:8081/user/" + order.getUserId();
String url = "http://userservice/user/" + order.getUserId();
// 2.2 发起调用
User user = restTemplate.getForObject(url, User.class);
// 3.存入order
order.setUser(user);
// 4.返回
return order;
}
}
spring会自动帮助我们从eureka-server端,根据userservice这个服务名称,获取实例列表,而后完成负载均衡。
❺总结
1.搭建EurekaServer
引入eureka-server依赖
添加@EnableEurekaServer注解
在application.yml中配置eureka地址
2.服务注册
- 引入eureka-client依赖
- 在application.yml中配置eureka地址
3.服务发现
- 引入eureka-client依赖
- 在application.yml中配置eureka地址
- 给RestTemplate添加@LoadBalanced注解
- 用服务提供者的服务名称远程调用
②Nacos
Nacos是阿里巴巴的产品,是 SpringCloudAlibaba 中的一个组件。相比 Eureka 功能更加丰富,在国内受欢迎程度较高。
❶安装
下载地址:https://github.com/alibaba/nacos
下载后解压即可,目录说明:
- log nacos生成日志说明
- bin nacos服务相关脚本目录,
- conf nacos的配置文件目录
- target nacos的启动依赖目录
- data nacos自带apache-derby数据库,data存放数据内容
# 启动命令 单体启动
sh startup.sh -m standalone
# 关闭命令
sh shutdown.sh
在浏览器输入地址即可访问:http://127.0.0.1:8848/nacos,默认的账号和密码都是nacos
如果你打不开这个网页 !多半是版本问题。
❷服务注册/发现
步骤一:引入依赖
在cloud-demo父工程的pom文件中的<dependencyManagement>中引入SpringCloudAlibaba的依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
然后在user-service和order-service中的pom文件中引入nacos-discovery依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
注意:不要忘了注释掉eureka的依赖。
步骤二:配置nacos地址
在user-service和order-service的application.yml中添加nacos地址:
spring:
cloud:
nacos:
server-addr: localhost:8848
注意:不要忘了注释掉eureka的地址
步骤三:重启
重启微服务后,登录nacos管理页面,可以看到微服务信息
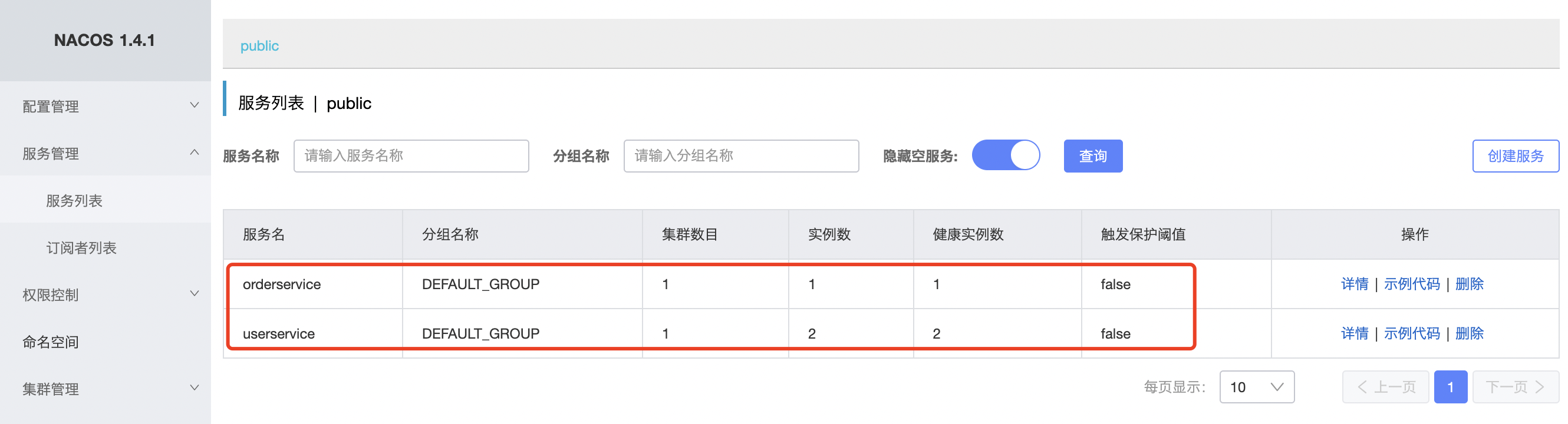
❸集群配置
⓵分级存储模型
一个服务可以有多个实例,例如我们的user-service,假如这些实例分布于全国各地的不同机房
| 实例 | 机房 |
|---|---|
| 127.0.0.1:8081 | 杭州 |
| 127.0.0.1:8082 | 杭州 |
| 127.0.0.1:8083 | 上海 |
Nacos就将同一机房内的实例划分为一个集群。也就是说,user-service是服务,一个服务可以包含多个集群,如杭州、上海、北京,每个集群下可以有多个实例,形成分级模型,如图:
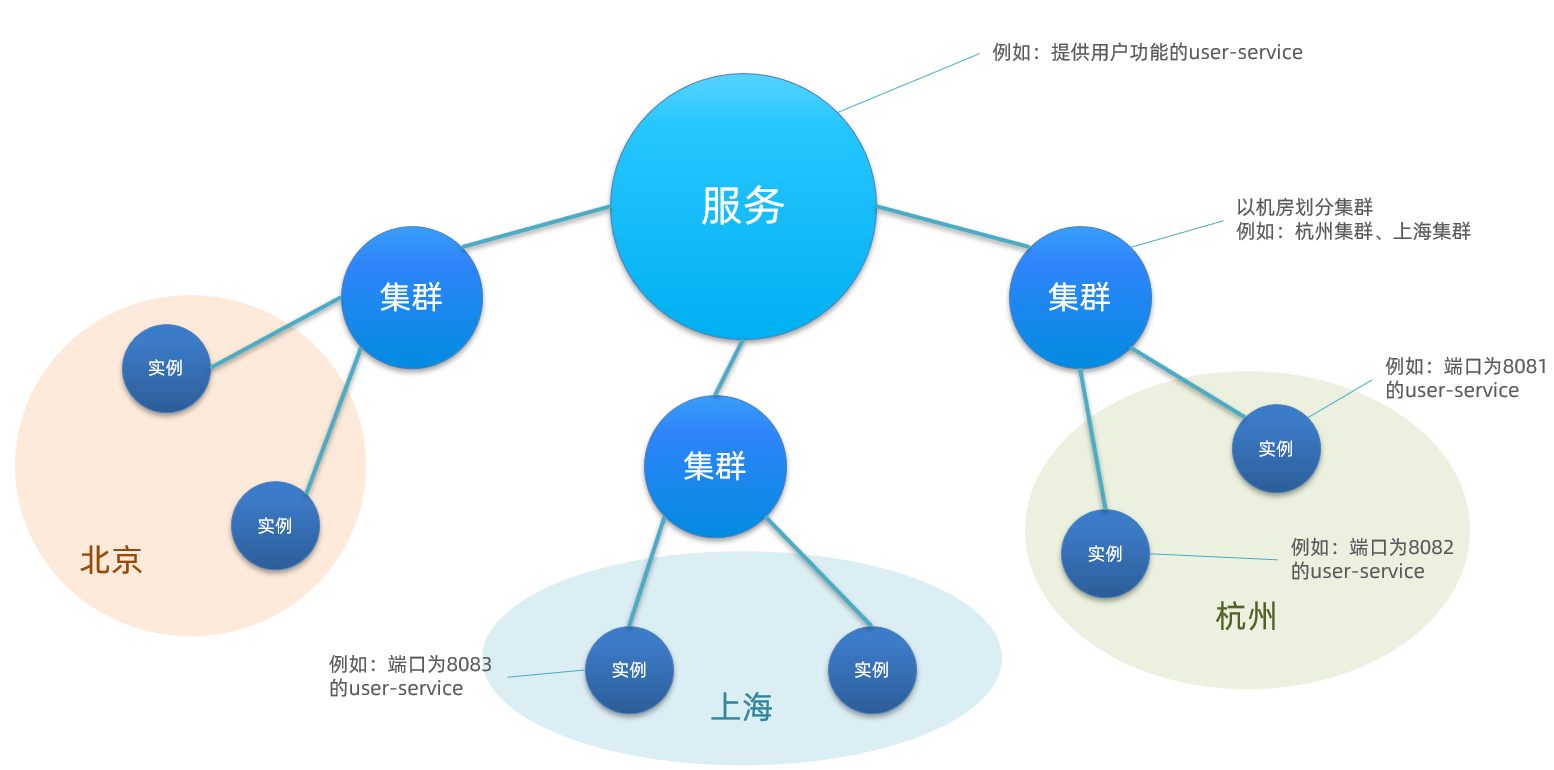
①一级是服务,例如user-service;②二级是集群,例如杭州或上海;③三级是实例,例如杭州机房的某台部署
微服务互相访问时,应该尽可能访问同集群实例,因为本地访问速度更快。当本集群内实例不可用时,才访问其它集群。例如:杭州机房内的order-service应该优先访问同机房的user-service。

⓶给user-service配置集群
修改user-service的application.yml文件,添加集群配置:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称
重启两个user-service实例后,我们可以在nacos控制台看到下面结果:

我们再次复制一个user-service启动配置UserApplication3,复制方式参考【上方搭建eureka-server步骤三】
添加VM属性:
-Dserver.port=8083 -Dspring.cloud.nacos.discovery.cluster-name=SH
启动UserApplication3后再次查看nacos控制台:

⓷同集群优先的负载均衡
负载均衡默认规则ZoneAvoidanceRule并不能实现根据同集群优先来实现负载均衡。因此Nacos中提供了一个NacosRule的实现,可以优先从同集群中挑选实例。
步骤一:给order-service配置集群信息
修改order-service的application.yml文件,添加集群配置:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称
步骤二:修改负载均衡规则
修改order-service的application.yml文件,修改负载均衡规则:
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则
NacosRule负载均衡策略
①优先选择同集群服务实例列表
②本地集群找不到提供者,才去其它集群寻找,并且会报警告
③确定了可用实例列表后,再采用随机负载均衡挑选实例
❹权重配置
实际部署中会出现这样的场景:服务器设备性能有差异,部分实例所在机器性能较好,另一些较差,我们希望性能好的机器承担更多的用户请求。但默认情况下NacosRule是同集群内随机挑选,不会考虑机器的性能问题。
因此,Nacos提供了权重配置来控制访问频率,权重越大则访问频率越高。在nacos控制台,找到user-service的实例列表,点击编辑,即可修改权重:
 |
 |
|---|
注意:如果权重修改为0,则该实例永远不会被访问,使用场景:进行实例的平滑更新
❺环境隔离
Nacos提供了namespace来实现环境隔离功能。
- nacos中可以有多个namespace
- namespace下可以有group、service等
- 不同namespace之间相互隔离,例如不同namespace的服务互相不可见
步骤一:创建namespace
默认情况下,所有service、group、data都在同一个namespace,名为public
| 添加一个namespace | 设置信息 |
|---|---|
 |
 |
就能在页面看到一个新的namespace:

步骤二:给微服务配置namespace
给微服务配置namespace只能通过修改配置来实现。例如,修改order-service的application.yml文件:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ
namespace: 492a7d5d-237b-46a1-a99a-fa8e98e4b0f9 # 命名空间,填ID
重启order-service后,访问控制台,可以看到下面的结果:
 |
 |
|---|
此时访问order-service,因为namespace不同,会导致找不到userservice,控制台会报错:

③Nacos与Eureka区别
Nacos的服务实例分为两种类型:
临时实例: 如果实例宕机超过一定时间,会从服务列表剔除,默认的实例类型。
非临时实例:如果实例宕机,不会从服务列表剔除,也可以叫永久实例。
配置一个服务实例为永久实例:
spring:
cloud:
nacos:
discovery:
ephemeral: false # 设置为非临时实例
Nacos和Eureka整体结构类似,服务注册、服务拉取、心跳等待,但是也存在一些差异:

| 共同点 | 不同点 |
|---|---|
| ①都支持服务注册和服务拉取 ②都支持服务提供者心跳方式做健康检测 |
①Nacos支持服务端主动检测提供者状态,临时实例采用心跳模式,非临时实例采用主动检测模式 ②临时实例心跳不正常会被剔除,非临时实例则不会被剔除 ③Nacos支持服务列表变更的消息推送模式,服务列表更新更及时 ④Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式 |
4.负载均衡-Ribbon
①负载均衡原理
SpringCloud底层利用Ribbon来实现负载均衡功能
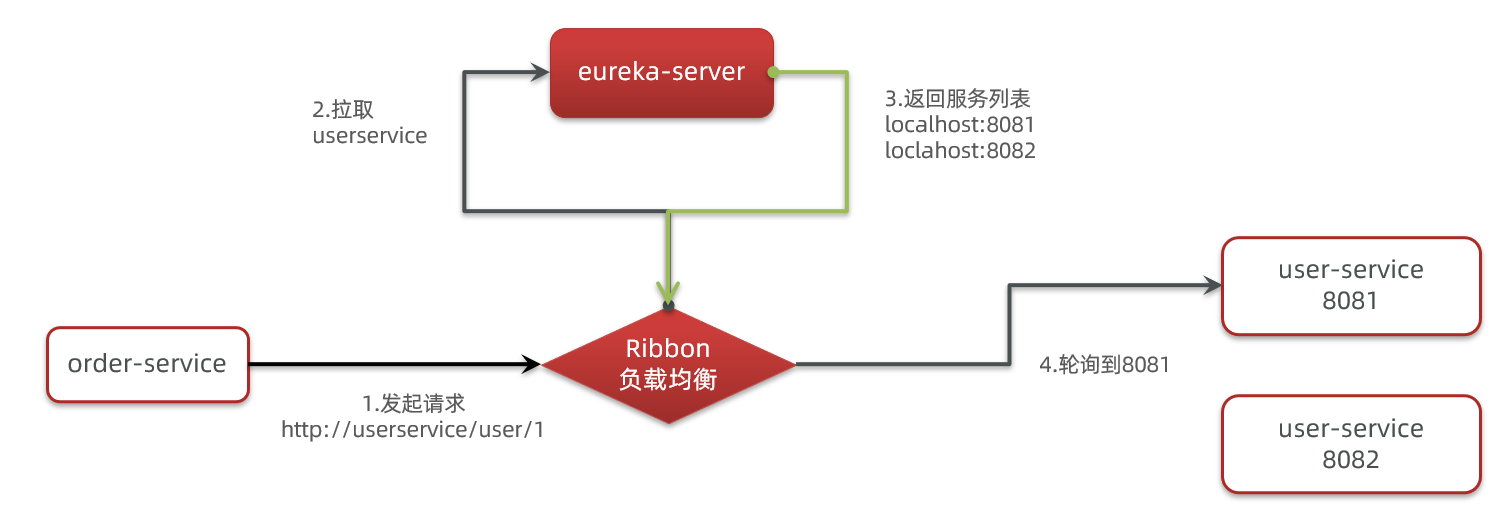
我们发出的请求明明是http://userservice/user/1,怎么变成了http://localhost:8081/user/1的呢?
显然有人帮我们根据service名称,获取到了服务实例的ip和端口。它就是
LoadBalancerInterceptor,这个类会在对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务id。我们进行源码跟踪:
❶LoadBalancerIntercepor
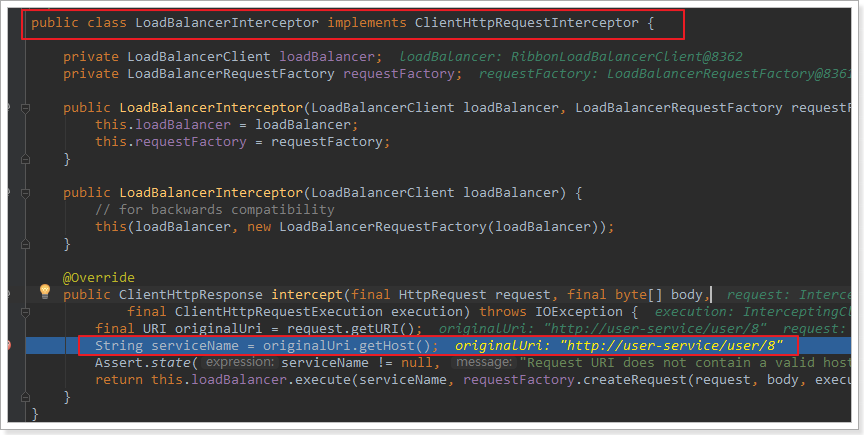
可以看到这里的intercept方法,拦截了用户的HttpRequest请求,然后做了几件事:
request.getURI():获取请求uri,本例中就是http://user-service/user/8originalUri.getHost():获取uri路径的主机名,其实就是服务id,user-servicethis.loadBalancer.execute():处理服务id,和用户请求。
这里的this.loadBalancer是LoadBalancerClient类型,我们继续跟入execute方法:
❷LoadBalancerClient
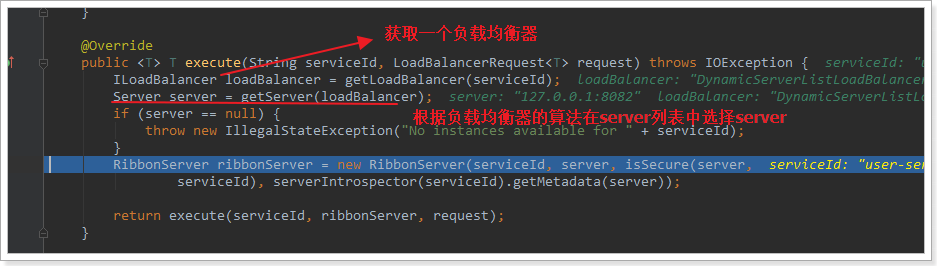
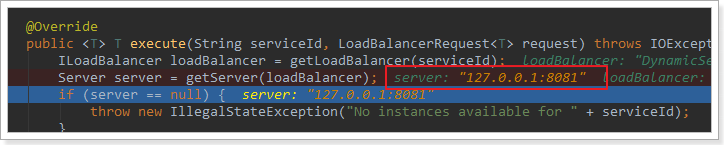
getLoadBalancer(serviceId):根据服务id获取ILoadBalancer,而ILoadBalancer会拿着服务id去eureka中获取服务列表并保存起来。getServer(loadBalancer):利用内置的负载均衡算法,从服务列表中选择一个。本例中,可以看到获取了8082端口的服务
放行后,再次访问并跟踪,发现获取的是8081,果然实现了负载均衡。
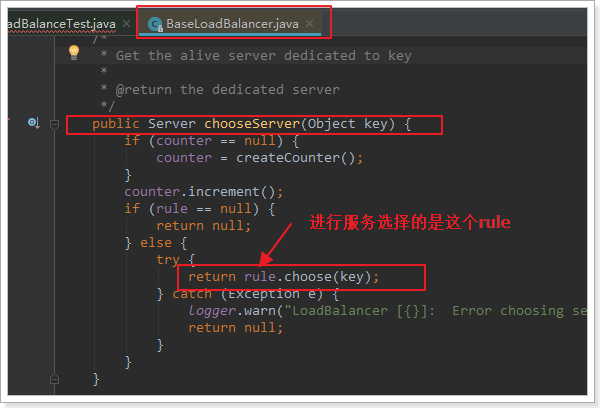
❸负载均衡策略IRule
在刚才的代码中,可以看到获取服务使通过一个getServer方法来做负载均衡:
我们继续跟入:

继续跟踪源码chooseServer方法,发现这么一段代码:
 |
 |
|---|
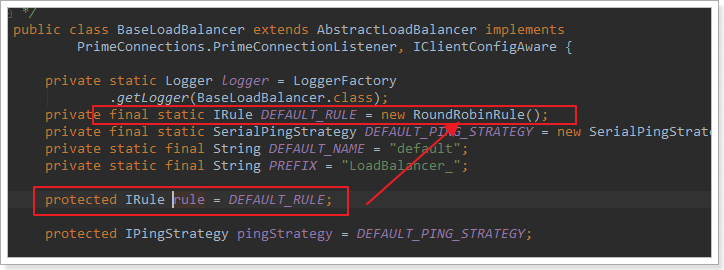
这里的rule默认值是一个RoundRobinRule,看类的介绍:
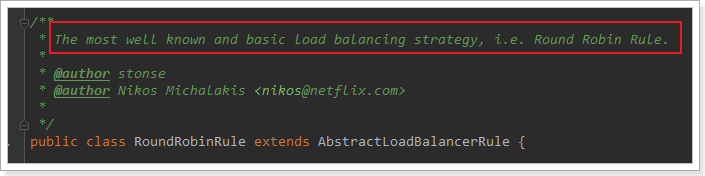
这不就是轮询的意思嘛。到这里,整个负载均衡的流程我们就清楚了。
❹总结
Ribbon的底层采用了一个拦截器,拦截了RestTemplate发出的请求,对地址做了修改。用一幅图来总结一下:

基本流程如下:
- 1.拦截我们的RestTemplate请求
http://userservice/user/1 - 2.RibbonLoadBalancerClient会从请求url中获取服务名称,也就是userservice
- 3.DynamicServerListLoadBalancer根据userservice到eureka拉取服务列表
- 4.eureka-server返回列表,localhost:8081、localhost:8082
- 5.IRule利用内置负载均衡规则,从列表中选择一个,例如localhost:8081
- 6.RibbonLoadBalancerClient修改请求地址,用localhost:8081替代userservice,得到
http://localhost:8081/user/1,发起真实请求
②负载均衡策略
负载均衡的规则都定义在IRule接口中,而IRule有很多不同的实现类:
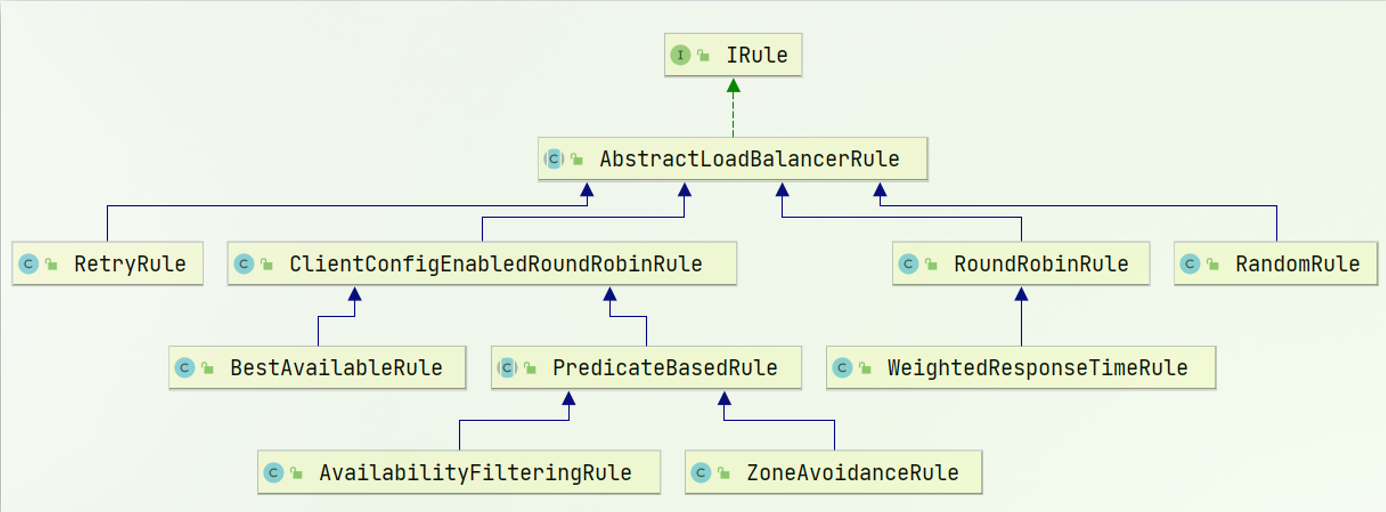
不同规则的含义如下:
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的<clientName>.<clientConfigNameSpace>.ActiveConnectionsLimit属性进行配置。 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
| RandomRule | 随机选择一个可用的服务器。 |
| RetryRule | 重试机制的选择逻辑 |
默认的实现就是ZoneAvoidanceRule,是一种轮询方案
自定义负载均衡策略
通过定义IRule实现可以修改负载均衡规则,有两种方式:
- 1.全局配置:在order-service中的OrderApplication类中,定义一个新的IRule
@Bean
public IRule randomRule(){
return new RandomRule();
}
- 2.单个配置:在order-service的application.yml文件中,添加新的配置也可以修改规则:
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
注意,一般用默认的负载均衡规则,不做修改。
③饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:
eager-load:
enabled: true
clients: userservice
5.服务远程调用②
②OpenFeign
前面利用RestTemplate发起远程调用的代码
String url = "http://localhost:8081/user/" + order.getUserId(); User user = restTemplate.getForObject(url, User.class);存在下面的问题:
代码可读性差,编程体验不统一
参数复杂URL难以维护
OpenFeign是一个声明式的http客户端,其作用就是帮助我们优雅的实现http请求的发送,解决上面提到的问题。
❶使用
步骤一:引入依赖
在order-service服务的pom文件中引入openfeign的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
使用 openfeign 依赖 ribbon,但是最新版的 openfeign 移除了ribbon ,因此如果单独使用openfeign需要引入ribbon,并进行配置。如果配合 eureka 或 nacos 则不用
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>
# 这个userservice是加了@FeignClient注解的类的name
userservice:
ribbon:
# 服务提供者的地址,不是服务注册中心的地址
listOfServers: http://localhost:8081
步骤二:添加注解
在order-service的启动类添加注解开启openfeign的功能:
@EnableFeignClients //开启feign
@MapperScan("cn.xxxx.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
}
步骤三:编写Feign的客户端
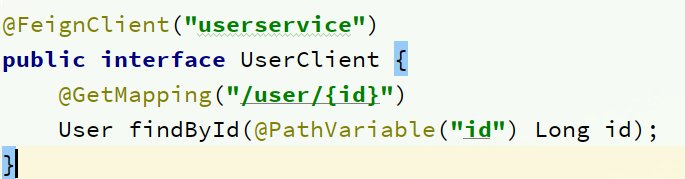
在order-service中新建一个接口,内容如下:
@FeignClient("userservice")
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
这个客户端主要是基于SpringMVC的注解来声明远程调用的信息,比如:
- 服务名称:userservice
- 请求方式:GET
- 请求路径:/user/{id}
- 请求参数:Long id
- 返回值类型:User
这样,Feign就可以帮助我们发送http请求,无需自己使用RestTemplate来发送了。
步骤四:实现远程调用
修改order-service中的OrderService类中的queryOrderById方法,使用Feign客户端代替RestTemplate:
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private UserClient userClient
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.利用Feign发起http请求,查询用户
User user = userClient.findById(order.getUserId());
// 3.存入order
order.setUser(user);
// 4.返回
return order;
}
}

总结
使用Feign的步骤:
① 引入依赖
② 添加@EnableFeignClients注解
③ 编写FeignClient接口
④ 使用FeignClient中定义的方法代替RestTemplate
❷配置
Feign可以支持很多的自定义配置,如下表所示:
| 类型 | 作用 | 说明 |
|---|---|---|
| feign.Logger.Level | 修改日志级别 | 包含四种不同的级别:NONE、BASIC、HEADERS、FULL |
| feign.codec.Decoder | 响应结果的解析器 | http远程调用的结果做解析,例如解析json字符串为java对象 |
| feign.codec.Encoder | 请求参数编码 | 将请求参数编码,便于通过http请求发送 |
| feign. Contract | 支持的注解格式 | 默认是SpringMVC的注解 |
| feign. Retryer | 失败重试机制 | 请求失败的重试机制,默认是没有,不过会使用Ribbon的重试 |
日志的级别分为四种:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间(推荐使用)
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
一般情况下,默认值就能满足我们使用,如果要自定义时,可以通过修改配置文件或者创建自定义@Bean覆盖默认Bean
修改配置文件方式
- 针对单个服务:
feign:
client:
config:
userservice: # 针对某个微服务的配置
loggerLevel: FULL # 日志级别
- 针对所有服务:
feign:
client:
config:
default: # 这里用default就是全局配置,如果是写服务名称,则是针对某个微服务的配置
loggerLevel: FULL # 日志级别
自定义Bean覆盖
也可以基于Java代码来修改日志级别,先声明一个类,然后声明一个Logger.Level的对象:
public class DefaultFeignConfiguration {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.BASIC; // 日志级别为BASIC
}
}
如果要全局生效,将其放到启动类的@EnableFeignClients这个注解中:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration.class)
如果是局部生效,则把它放到对应的@FeignClient这个注解中:
@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration.class)
❸优化
Feign底层发起http请求,依赖于其它的框架。其底层客户端实现包括:
URLConnection:默认实现,不支持连接池
Apache HttpClient :支持连接池
OKHttp:支持连接池
因此提高Feign的性能主要手段就是使用连接池代替默认的URLConnection。这里我们用Apache的HttpClient来演示。
步骤一:引入依赖
在order-service的pom文件中引入Apache的HttpClient依赖:
<!--httpClient的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
步骤二:配置连接池
在order-service的application.yml中添加配置:
feign:
client:
config:
default: # default全局的配置
loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息
httpclient:
enabled: true # 开启feign对HttpClient的支持
max-connections: 200 # 最大的连接数
max-connections-per-route: 50 # 每个路径的最大连接数
❹最佳实践
所谓最近实践,就是使用过程中总结的经验,最好的一种使用方式。仔细可以发现,Feign的客户端与服务提供者的controller代码非常相似:
| UserClient | UserController |
|---|---|
 |
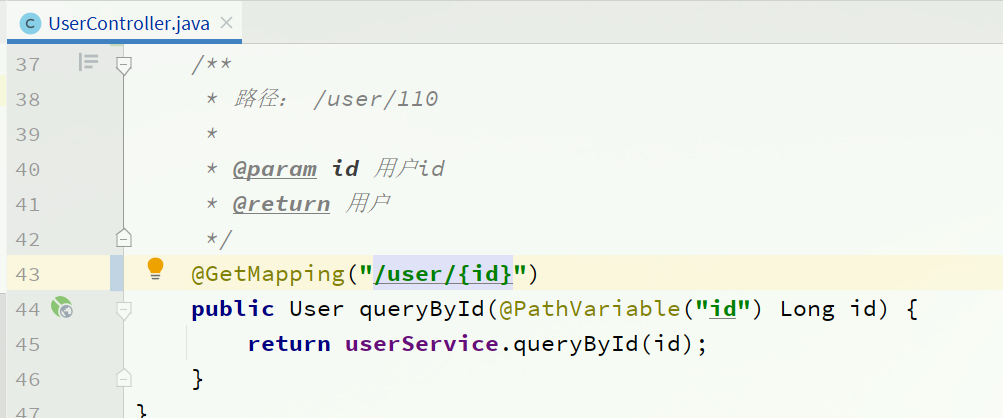 |
有没有一种办法简化这种重复的代码编写呢?
方案一:继承方式
一样的代码可以通过继承来共享:
- 1.定义一个API接口,利用定义方法,并基于SpringMVC注解做声明。
- 2.Feign客户端和Controller都集成该接口
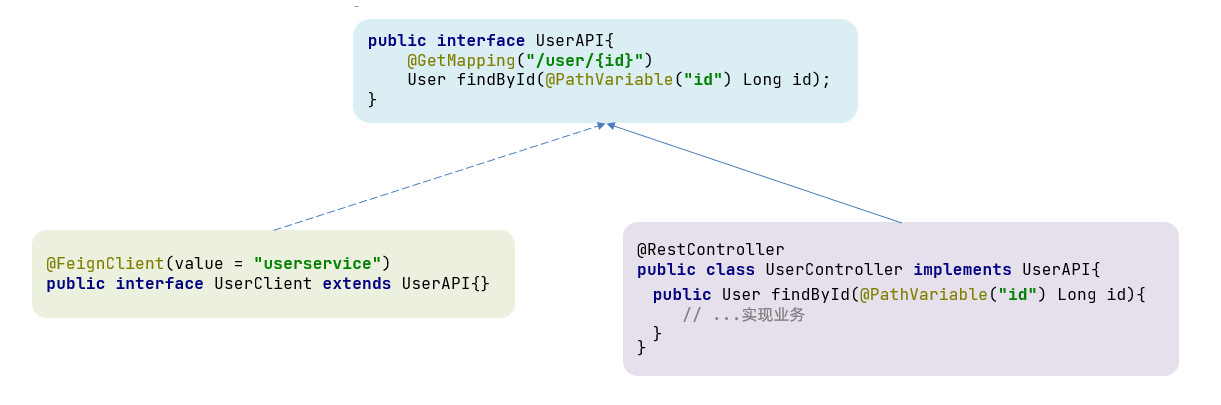 优点:
优点:
- 简单
- 实现了代码共享
缺点:
服务提供方、服务消费方紧耦合
参数列表中的注解映射并不会继承,因此Controller中必须再次声明方法、参数列表、注解
方案二:抽取方式
将Feign的Client抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块中,提供给所有消费者使用。
例如,将UserClient、User、Feign的默认配置都抽取到一个feign-api包中,所有微服务引用该依赖包,即可直接使用。

步骤一:抽取
首先创建一个module,命名为feign-api,在feign-api中然后引入feign的starter依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
然后,order-service中编写的UserClient、User、DefaultFeignConfiguration都复制到feign-api项目中

步骤二:在order-service中使用feign-api
首先,删除order-service中的UserClient、User、DefaultFeignConfiguration等类或接口。在order-service的pom文件中中引入feign-api的依赖:
<dependency>
<groupId>cn.itcast.demo</groupId>
<artifactId>feign-api</artifactId>
<version>1.0</version>
</dependency>
修改order-service中的所有与上述三个组件有关的导包部分,改成导入feign-api中的包
步骤三:重启测试
重启后,发现服务报错了:

这是因为UserClient现在在cn.itcast.feign.clients包下,而order-service的@EnableFeignClients注解是在cn.itcast.order包下,不在同一个包,无法扫描到UserClient。
步骤四:解决扫描包问题
方式一:指定Feign应该扫描的包:
@EnableFeignClients(basePackages = "cn.itcast.feign.clients")
方式二:指定需要加载的Client接口:
@EnableFeignClients(clients = {UserClient.class})
6.统一配置管理
①Nacos
Nacos除了可以做注册中心,同样可以做配置管理来使用。当微服务部署的实例越来越多,达到数十、数百时,逐个修改微服务配置就会让人抓狂,而且很容易出错。我们需要一种统一配置管理方案,可以集中管理所有实例的配置。
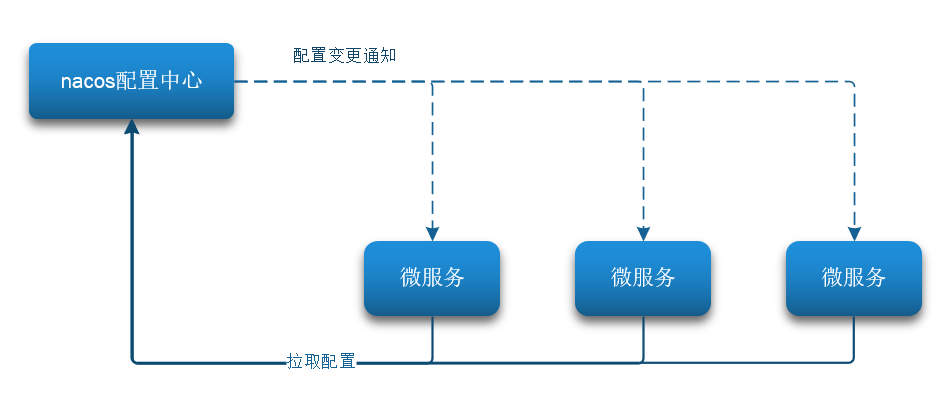
Nacos一方面可以将配置集中管理,另一方可以在配置变更时,及时通知微服务,实现配置的热更新。
❶统一配置管理
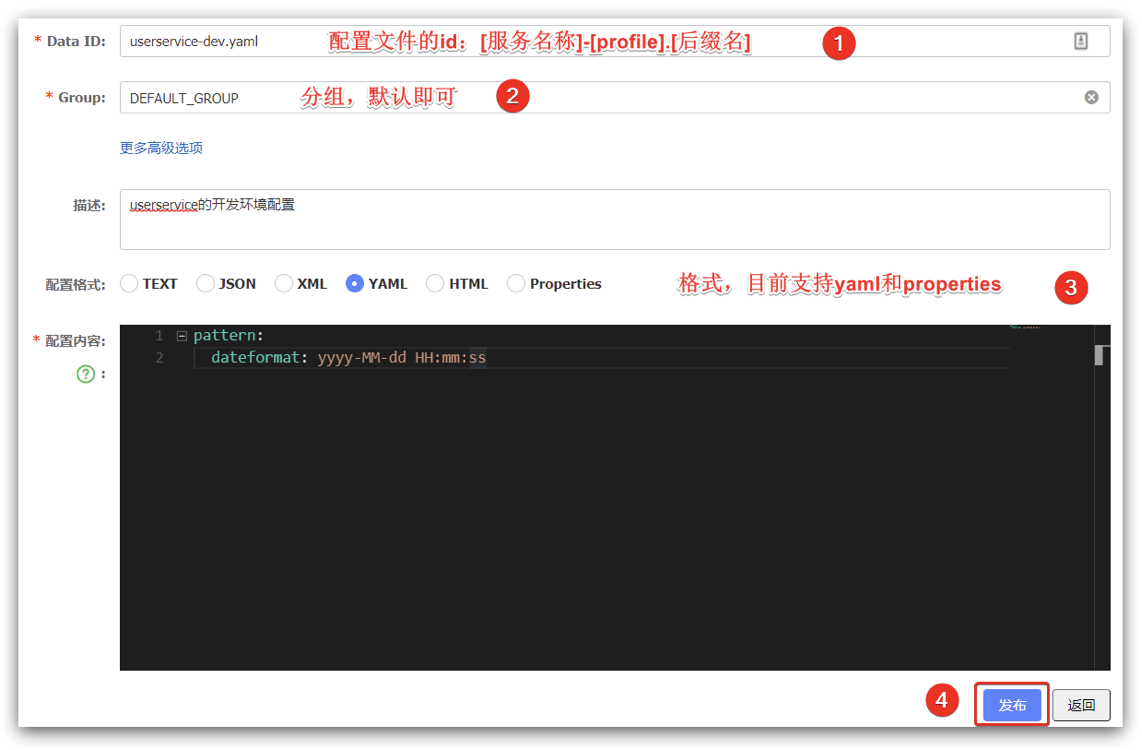
步骤一:在nacos中添加配置文件
| 1.在Nacos中添加配置信息 | 2.在弹出表单中填写配置信息 |
|---|---|
 |
 |
步骤二:从微服务拉取配置
微服务要拉取nacos中管理的配置,并且与本地的application.yml配置合并,才能完成项目启动。
但如果尚未读取application.yml,又如何得知nacos地址呢?
因此spring引入了一种新的配置文件:bootstrap.yaml文件,会在application.yml之前被读取,流程如下:
| 传统读取配置 |  |
|---|---|
| nacos管理配置 | 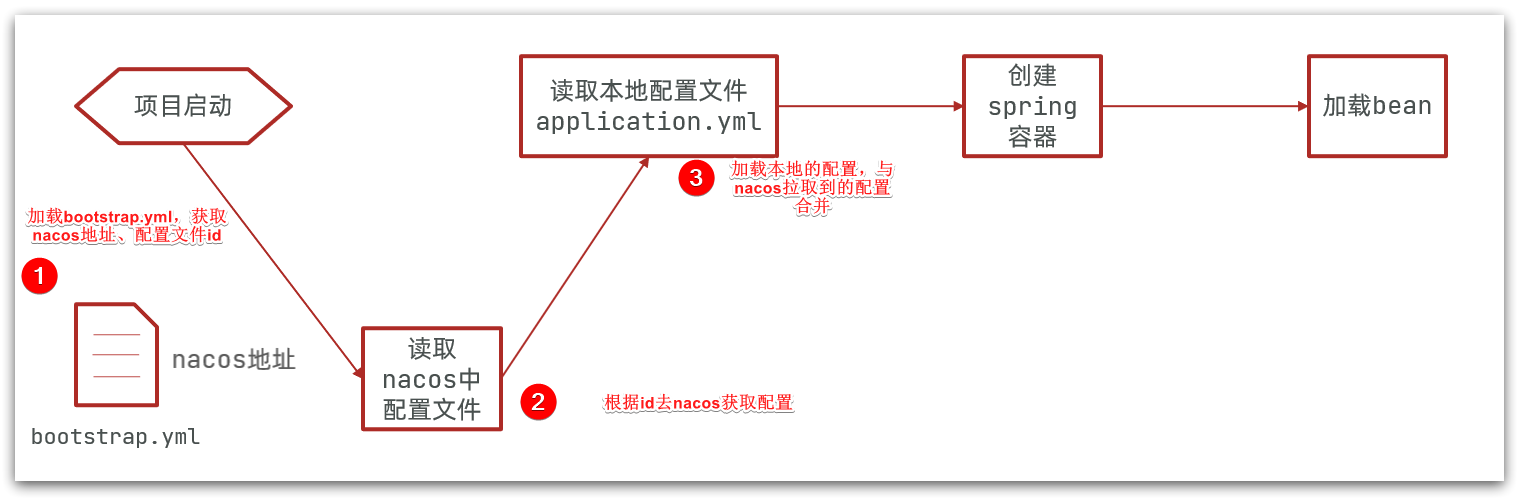 |
1.引入Nacos的配置管理客户端依赖
<!--nacos配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
2.在userservice的resource目录添加一个bootstrap.yml文件,这个文件是引导文件,优先级高于application.yml:
spring:
application:
name: userservice # 服务名称
profiles:
active: dev #开发环境,这里是dev
cloud:
nacos:
server-addr: localhost:8848 # Nacos地址
config:
file-extension: yaml # 文件后缀名
这里会根据spring.cloud.nacos.server-addr获取nacos地址,再根据
${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}作为文件id,来读取配置。本例中,就是去读取userservice-dev.yaml

3.在user-service中的UserController中添加业务逻辑,读取pattern.dateformat配置
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Value("${pattern.dateformat}")
private String dateformat;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));
}
}
访问页面http://127.0.0.1:8081/user/now即可看到时间
总结:将配置交给Nacos管理的步骤
①在Nacos中添加配置文件
②在微服务中引入nacos的config依赖
③在微服务中添加bootstrap.yml,配置nacos地址、当前环境、服务名称、文件后缀名。
❷配置热更新
我们最终的目的,是修改nacos中的配置后,微服务无需重启即可让配置生效,也就是配置热更新。
要实现配置热更新,可以使用两种方式:
方式一:通过 Spring Cloud 原生注解 @RefreshScope 实现配置自动更新
@RefreshScope //添加注解
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Value("${pattern.dateformat}")
private String dateformat;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));
}
}
方式二:使用@ConfigurationProperties注解代替@Value注解
在user-service服务中,添加一个类,读取patterrn.dateformat属性:
@Component
@Data
@ConfigurationProperties(prefix = "pattern")
public class PatternProperties {
private String dateformat;
}
在UserController中使用这个类代替@Value:
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private PatternProperties patternProperties;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties.getDateformat()));
}
}
❸配置共享
其实微服务启动时,会去nacos读取多个配置文件,例如:
[spring.application.name]-[spring.profiles.active].yaml,例如:userservice-dev.yaml[spring.application.name].yaml,例如:userservice.yaml
而[spring.application.name].yaml不包含环境,因此可以被多个环境共享。
例如:在nacos配置3个文件:userservice-dev.yaml、userservice-test.yaml、userservice.yaml
UserApplication(8081)使用的profile是dev,UserApplication2(8082)使用的profile是test,运行后不管是dev,还是test环境,都读取到了userservice.yaml中属性的值。
但是当nacos和服务本地同时出现相同属性时,优先级有高低之分:userservice-dev.yaml > userservice.yaml > application.yml

多服务共享配置
不同微服务之间可以共享配置文件,通过下面的两种方式来指定
方式一:
spring:
application:
name: userservice # 服务名称
profiles:
active: dev #开发环境,这里是dev
cloud:
nacos:
server-addr: localhost:8848 # Nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 多微服务间共享的配置列表
- dataId: common.yaml # 要共享的配置文件id
方式二:
spring:
application:
name: userservice # 服务名称
profiles:
active: dev #开发环境,这里是dev
cloud:
nacos:
server-addr: localhost:8848 # Nacos地址
config:
file-extension: yaml # 文件后缀名
extends-configs: # 多微服务间共享的配置列表
- dataId: extend.yaml # 要共享的配置文件id
多种配置的优先级:

❹搭建Nacos集群
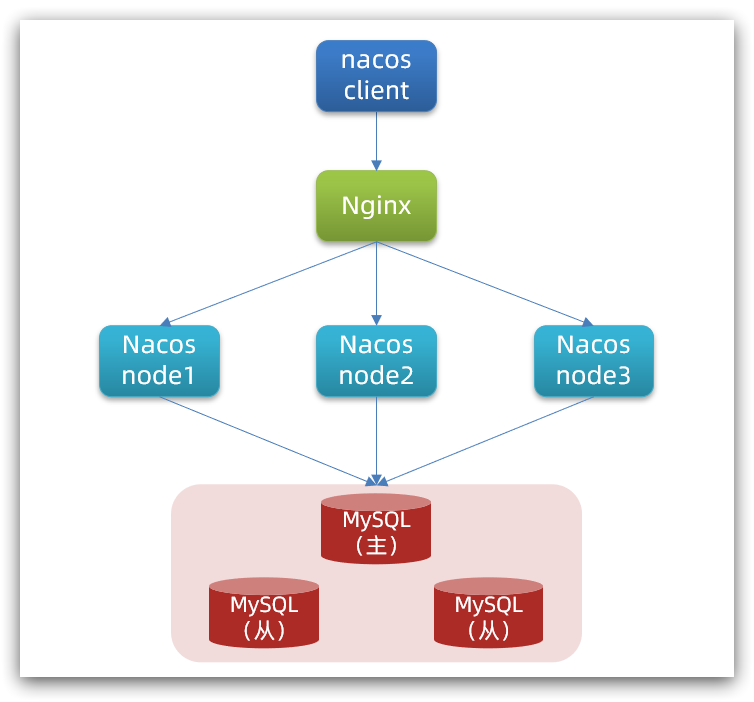
| 节点 | ip | port |
|---|---|---|
| nacos1 | 192.168.150.1 | 8845 |
| nacos2 | 192.168.150.1 | 8846 |
| nacos3 | 192.168.150.1 | 8847 |
⓵初始化数据库
Nacos默认数据存储在内嵌数据库Derby中,不属于生产可用的数据库。官方推荐的最佳实践是使用带有主从的高可用数据库集群。这里我们以单点的数据库为例。
首先新建一个数据库,命名为nacos,而后导入官方提供的SQL:nacos/schema.sql
⓶部署配置nacos
下载nacos后,进入nacos的conf目录,修改配置文件cluster.conf.example,重命名为cluster.conf
然后添加内容:
127.0.0.1:8845
127.0.0.1.8846
127.0.0.1.8847
然后修改application.properties文件,添加数据库配置
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=root
db.password.0=root
⓷启动nacos集群
将nacos文件夹复制三份,分别命名为:nacos1、nacos2、nacos3;然后分别修改三个文件夹中的application.properties
nacos1:
server.port=8845
nacos2:
server.port=8846
nacos3:
server.port=8847
然后分别启动三个nacos节点:startup.cmd
⓸nginx反向代理
下载nginx后,修改conf/nginx.conf文件,配置如下:
upstream nacos-cluster {
server 127.0.0.1:8845;
server 127.0.0.1:8846;
server 127.0.0.1:8847;
}
server {
listen 80;
server_name localhost;
location /nacos {
proxy_pass http://nacos-cluster;
}
}
而后在浏览器访问:http://localhost/nacos即可。
代码中application.yml文件配置如下:
spring:
cloud:
nacos:
server-addr: localhost:80 # Nacos地址
⓹优化
实际部署时,需要给做反向代理的nginx服务器设置一个域名,这样后续如果有服务器迁移,nacos的客户端也无需更改配置
Nacos的各个节点应该部署到多个不同服务器,做好容灾和隔离
7.统一网关路由
①简介
Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等响应式编程和事件流技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。
Gateway网关是我们服务的守门神,所有微服务的统一入口。网关的核心功能特性:
- 路由和负载均衡
- 一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫做路由。当然路由的目标服务有多个时,还需要做负载均衡。
- 权限控制
- 网关作为微服务入口,需要校验用户是是否有请求资格,如果没有则进行拦截。
- 限流
- 当请求流量过高时,在网关中按照下流的微服务能够接受的速度来放行请求,避免服务压力过大。

在SpringCloud中网关的实现包括两种:
- gateway
- zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。
②快速入门
下面,我们就演示下网关的基本路由功能。基本步骤如下:
- 创建新模块,引入网关依赖
- 编写启动类
- 编写基础配置和路由规则
- 启动网关服务进行测试
❶创建新模块,引入网关依赖
创建服务:
引入依赖:
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
❷编写启动类
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
❸编写基础配置和路由规则
创建application.yml文件,内容如下:
server:
port: 10010 # 网关端口
spring:
application:
name: gateway # 服务名称
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 网关路由配置
- id: user-service # 路由id,自定义,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址
uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
我们将符合Path 规则的一切请求,都代理到 uri参数指定的地址。
本例中,我们将 /user/**开头的请求,代理到lb://userservice,lb是负载均衡,根据服务名拉取服务列表,实现负载均衡。
❹启动网关服务进行测试
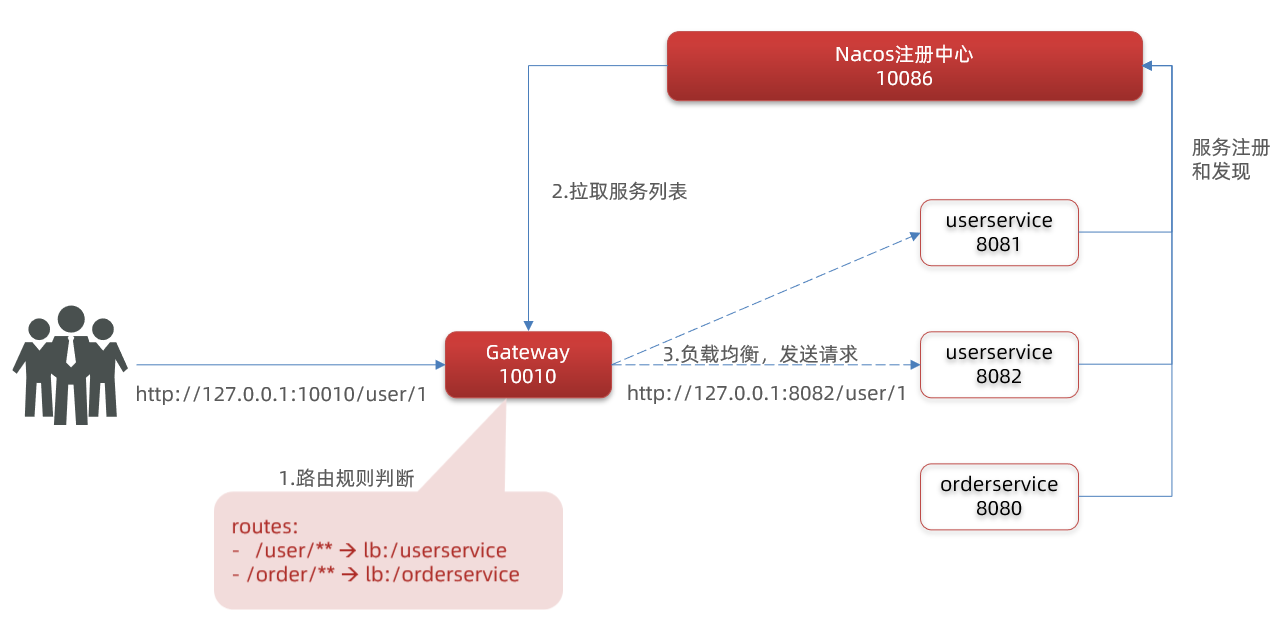
启动网关,访问http://localhost:10010/user/1时,符合/user/**规则,请求转发到uri:http://userservice/user/1,得到了结果:

整个访问的流程如下:
❺总结
网关搭建步骤:
创建项目,引入nacos服务发现和gateway依赖
配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括:
路由id:路由的唯一标示
路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
路由断言(predicates):判断路由的规则
路由过滤器(filters):对请求或响应做处理
③断言工厂
我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断的条件
例如Path=/user/**是按照路径匹配,这个规则是由
org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory类来
处理的,像这样的断言工厂在SpringCloudGateway还有十几个:
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 |
我们只需要掌握Path这种路由工程就可以了。
④过滤工厂
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理:

❶路由过滤器的种类
Spring提供了31种不同的路由过滤器工厂。例如:
| 名称 | 说明 |
|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果中添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 |
| RequestRateLimiter | 限制请求的流量 |
| …… | …… |
❷响应头过滤器
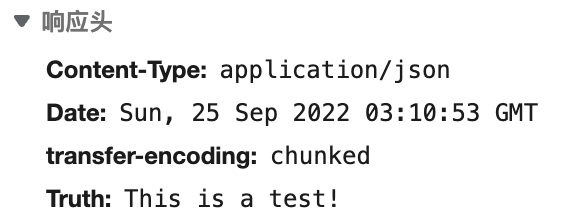
下面我们以AddResponseHeader 为例来讲解。
需求:给所有进入userservice的请求添加一个请求头:Truth=This is a test !
只需要修改gateway服务的application.yml文件,添加路由过滤即可:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**
filters: # 过滤器
- AddResponseHeader=Truth, This is a test! # 添加请求头
当前过滤器写在userservice路由下,因此仅仅对访问userservice的请求有效。
❸默认过滤器
如果要对所有的路由都生效,则可以将过滤器工厂写到default下。格式如下:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
default-filters: # 默认过滤项
- AddResponseHeader=Truth, This is a test!
❹总结
过滤器的作用是什么?
① 对路由的请求或响应做加工处理,比如添加请求头
② 配置在路由下的过滤器只对当前路由的请求生效
defaultFilters的作用是什么?
- ① 对所有路由都生效的过滤器
⑤全局过滤器
上一节学习的过滤器,网关提供了31种,但每一种过滤器的作用都是固定的。如果我们希望拦截请求,做自己的业务逻辑则没办法实现。
❶全局过滤器作用
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。
定义方式是实现GlobalFilter接口。
public interface GlobalFilter {
/**
* 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理
*
* @param exchange 请求上下文,里面可以获取Request、Response等信息
* @param chain 用来把请求委托给下一个过滤器
* @return {@code Mono<Void>} 返回标示当前过滤器业务结束
*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}
在filter中编写自定义逻辑,可以实现下列功能:
- 登录状态判断
- 权限校验
- 请求限流等
❷自定义全局过滤器
需求:定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件:
参数中是否有authorization,
authorization参数值是否为admin
如果同时满足则放行,否则拦截
实现:在gateway中定义一个过滤器:
package cn.itcast.gateway.filters;
@Order(-1)
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取请求参数
MultiValueMap<String, String> params = exchange.getRequest().getQueryParams();
// 2.获取authorization参数
String auth = params.getFirst("authorization");
// 3.校验
if ("admin".equals(auth)) {
// 放行
return chain.filter(exchange);
}
// 4.拦截
// 4.1.禁止访问,设置状态码
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
// 4.2.结束处理
return exchange.getResponse().setComplete();
}
}
❸过滤器执行顺序
请求进入网关会碰到三类过滤器:DefaultFilter、当前路由的过滤器、GlobalFilter
请求路由后,会将三个过滤器合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
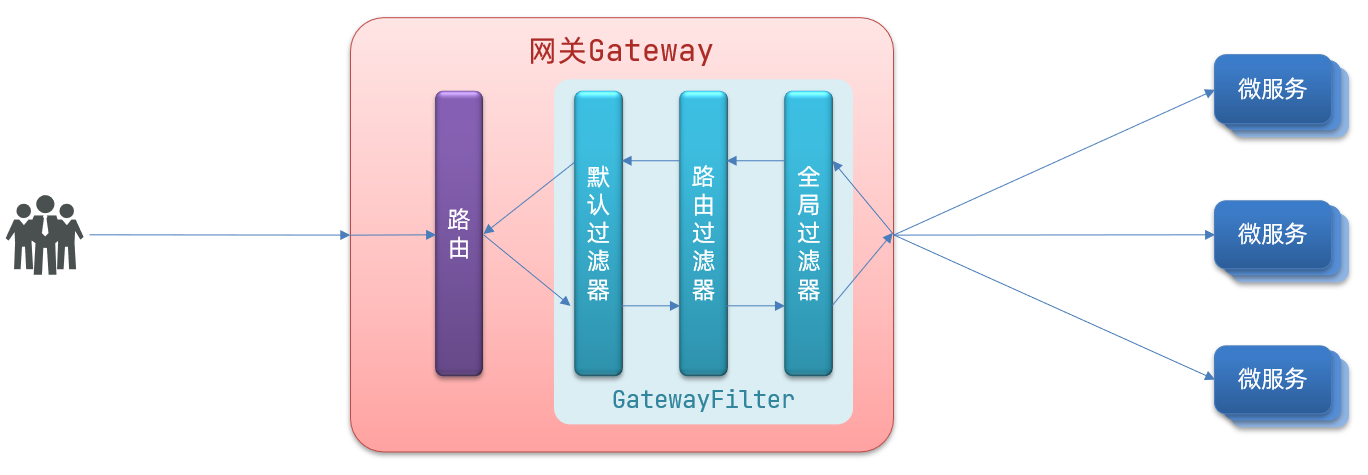
排序的规则是什么呢?
- 每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
- 路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
- 当过滤器的order值一样时,会按照 defaultFilter > 路由过滤器 > GlobalFilter的顺序执行。
详细内容,可以查看源码:
org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator#getFilters()方法是先加载defaultFilters,然后再加载某个route的filters,然后合并。
org.springframework.cloud.gateway.handler.FilteringWebHandler#handle()方法会加载全局过滤器,与前面的过滤器合并后根据order排序,组织过滤器链
❹总结
全局过滤器的作用是什么?
- 对所有路由都生效的过滤器,并且可以自定义处理逻辑
实现全局过滤器的步骤?
①实现GlobalFilter接口
②添加@Order注解或实现Ordered接口
③编写处理逻辑
路由过滤器、defaultFilter、全局过滤器的执行顺序?
①order值越小,优先级越高
②当order值一样时,顺序是defaultFilter > 局部的路由过滤器 > 全局过滤器
⑥跨域问题
❶什么是跨域问题
跨域:域名不一致就是跨域,主要包括:
域名不同:
www.taobao.com和www.taobao.org域名相同,端口不同:
localhost:8080和localhost8081
跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
解决方案:CORS。不知道的小伙伴可以查看https://www.ruanyifeng.com/blog/2016/04/cors.html
❷模拟跨域问题
编写一个页面,并在VScode中启动 live-server --port=8090
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<pre>这是一个测试!</pre>
</body>
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
<script>
axios.get("http://localhost:10010/user/1?authorization=admin")
.then(resp => console.log(resp.data))
.catch(err => console.log(err))
</script>
</html>
可以在浏览器控制台看到下面的错误:

从localhost:8090访问localhost:10010,端口不同,显然是跨域的请求。
❸解决跨域问题
在gateway服务的application.yml文件中,添加下面的配置:
spring:
cloud:
gateway:
# .......
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]': # 拦截一切请求
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
- "https://jwt1399.top"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期
8.Docker技术
镜像(Image):将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像
容器(Container):镜像中的应用程序运行后形成的进程就是容器
仓库(Repository):一个镜像托管的服务器,可以从中上传、拉取镜像。
数据卷(volume):是一个虚拟目录,指向宿主机文件系统中的某个目录。
①镜像操作
❶镜像名称
- 镜名称一般分两部分组成:[repository]:[tag]。
- 在没有指定tag时,默认是latest,代表最新版本的镜像
❷镜像命令

docker images # 查看镜像
docker inspect # 查看具体镜像
docker rmi # 删除镜像
docker pull # 拉取镜像
docker push # 推送镜像
docker save # 导出镜像
docker load # 加载镜像
❸镜像案例
需求:从DockerHub中拉取一个nginx镜像并查看
# 1)首先去镜像仓库搜索nginx镜像,比如DockerHub
# 2)根据查看到的镜像名称,拉取自己需要的镜像
docker pull nginx
# 3)查看拉取到的镜像
docker images
需求:利用docker save将nginx镜像导出磁盘,然后再通过load加载回来
# 1)利用docker xx --help命令查看语法,例如,查看save命令用法,可以输入命令:
docker save --help
# 2)使用docker save导出镜像到磁盘
docker save -o nginx.tar nginx:latest
# 3)使用docker load加载镜像
# 先删除本地的nginx镜像:
docker rmi nginx:latest
# 然后运行命令,加载本地文件
docker load -i nginx.tar
②容器操作
❶容器状态
容器保护三个状态:
- 运行:进程正常运行
- 暂停:进程暂停,CPU不再运行,并不释放内存
- 停止:进程终止,回收进程占用的内存、CPU等资源
❷容器命令
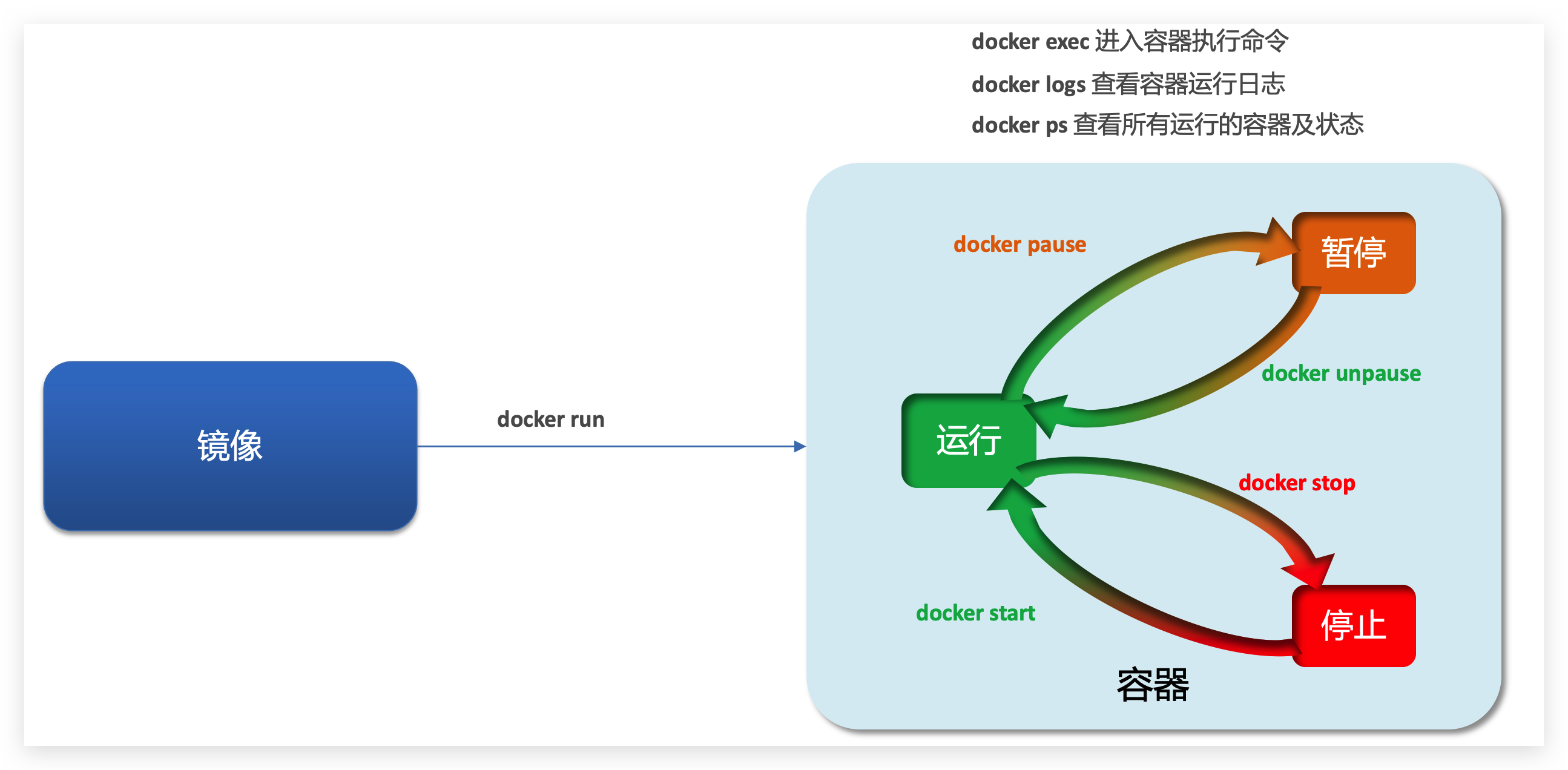
docker ps # 查看容器状态, -a 查看所有容器,包括已经停止的
docker run # 创建并运行一个容器,处于运行状态
docker pause # 让一个运行的容器暂停
docker unpause # 让一个容器从暂停状态恢复运行
docker stop # 停止一个运行的容器
docker start # 让一个停止的容器再次运行
docker rm # 删除一个容器
docker exec # 进入容器执行命令
docker logs # 查看容器日志的命令,-f 参数可以持续查看日志
❸容器案例
需求:创建并运行一个nginx容器
docker run --name mn -p 80:80 -d nginx
命令解读:
- docker run :创建并运行一个容器
- –name : 给容器起一个名字,比如叫做mn
- -p :将宿主机端口与容器端口映射,冒号左侧是宿主机端口,右侧是容器端口
- -d:后台运行容器
- nginx:镜像名称,例如nginx
需求:进入Nginx容器,修改HTML文件内容,添加”哈喽,你好呀!”
1)进入容器。进入我们刚刚创建的nginx容器的命令为:
docker exec -it mn bash
命令解读:
docker exec :进入容器内部,执行一个命令
-it : 给当前进入的容器创建一个标准输入、输出终端,允许我们与容器交互
mn :要进入的容器的名称
bash:进入容器后执行的命令,bash是一个linux终端交互命令
2)进入nginx的HTML所在目录
查看DockerHub网站中的nginx页面,可以知道nginx的html目录位置在/usr/share/nginx/html
cd /usr/share/nginx/html
3)修改index.html的内容
容器内没有vi命令,无法直接修改,我们用下面的命令来修改:
sed -i -e 's#Welcome to nginx#哈喽,你好呀!#g' -e 's###g' index.html
在浏览器访问 127.0.0.1:80 ,即可看到结果
③数据卷
❶简介
数据卷(volume)是一个虚拟目录,指向宿主机文件系统中的某个目录。
数据卷的作用:将容器与数据分离,解耦合,方便操作容器内数据,保证数据安全

一旦完成数据卷挂载,对容器的一切操作都会作用在数据卷对应的宿主机目录了。这样,我们操作宿主机的/var/lib/docker/volumes/html目录,就等于操作容器内的/usr/share/nginx/html目录了
❷数据集命令
docker volume create # 创建一个数据卷
docker volume ls # 列出所有的volume
docker volume inspect # 显示一个或多个volume的信息
docker volume rm # 删除一个或多个指定的volume
docker volume prune # 删除未使用的volume
❸创建和查看数据卷
需求:创建一个数据卷,并查看数据卷在宿主机的目录位置
① 创建数据卷
docker volume create html
② 查看所有数据
docker volume ls
③ 查看数据卷详细信息卷
docker volume inspect html
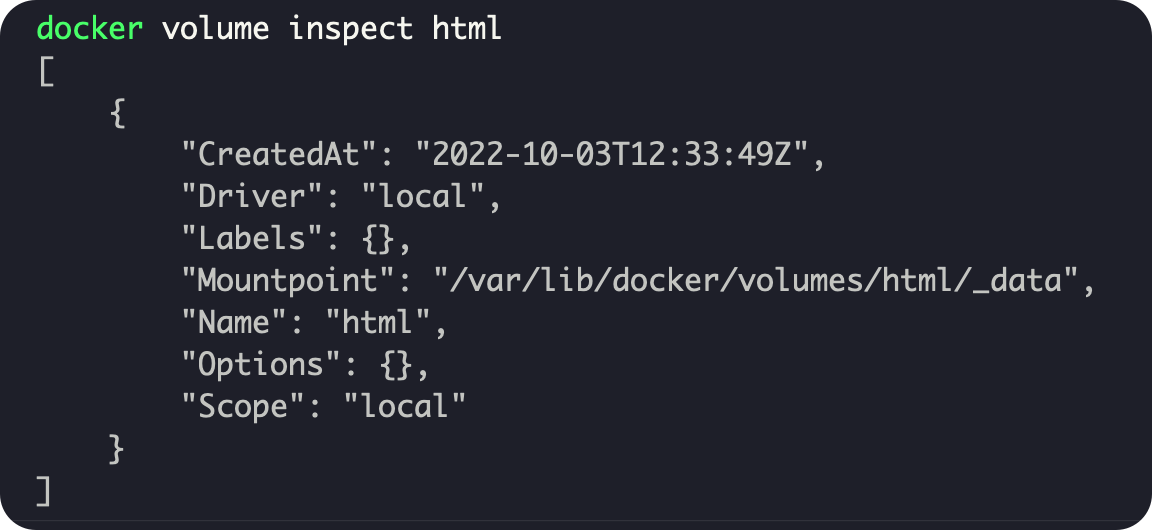
可以看到,我们创建的html这个数据卷关联的宿主机目录为/var/lib/docker/volumes/html/_data目录。
❹挂载数据卷
我们在创建容器时,可以通过 -v 参数来挂载一个数据卷到某个容器内目录,命令格式如下:
docker run \
--name mn \
-v html:/root/html \
-p 8080:80
nginx \
这里的-v就是挂载数据卷的命令:
-v html:/root/html:把html数据卷挂载到容器内的/root/html这个目录中
❺案例:给Nginx挂载数据卷
需求:创建一个nginx容器,修改容器内的html目录内的index.html内容
① 创建容器并挂载数据卷到容器内的HTML目录
docker run --name mn -v html:/usr/share/nginx/html -p 80:80 -d nginx
② 进入html数据卷所在位置,并修改HTML内容
# 查看html数据卷的位置
docker volume inspect html
# 进入该目录
cd /var/lib/docker/volumes/html/_data
# 修改文件
vi index.html
注:mac下 docker 实际是在vm里又加了一层,因此需要进入 vm 才能执行上面操作
docker run -it --privileged --pid=host justincormack/nsenter1
❻案例-给MySQL挂载本地目录
容器不仅仅可以挂载数据卷,也可以直接挂载到宿主机目录上。关联关系如下:
- 带数据卷模式:宿主机目录 –> 数据卷 —> 容器内目录
- 直接挂载模式:宿主机目录 —> 容器内目录
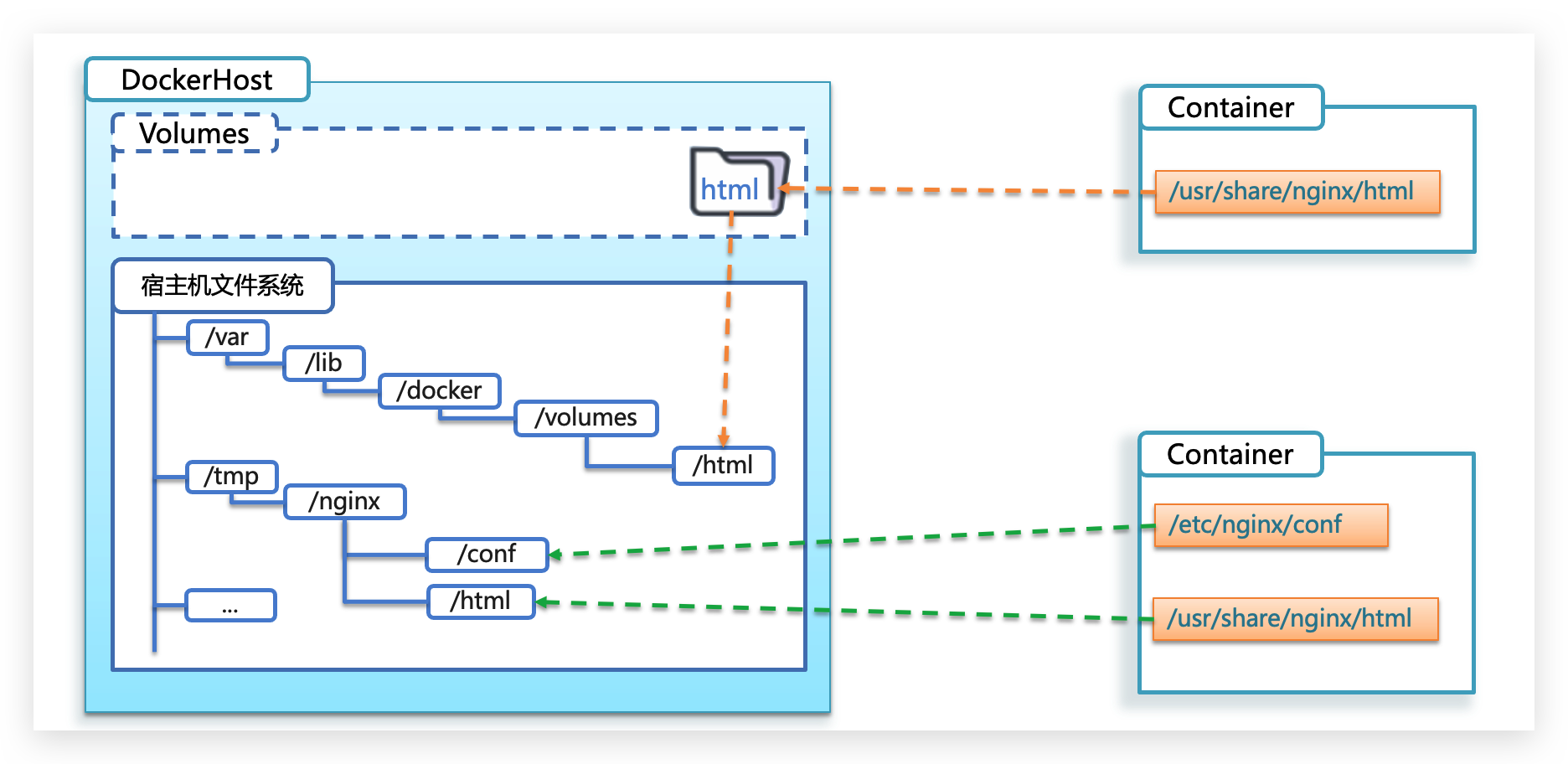
语法:目录挂载与数据卷挂载的语法是类似的:
- -v [宿主机目录]:[容器内目录]
- -v [宿主机文件]:[容器内文件]
需求:创建并运行一个MySQL容器,将宿主机目录直接挂载到容器
1)拉取mysql镜像
docker pull mysql
2)创建目录/tmp/mysql/data
mkdir -p /tmp/mysql/data
3)创建目录/tmp/mysql/conf,将提供的hmy.cnf文件上传到/tmp/mysql/conf
mkdir -p /tmp/mysql/conf
4)去DockerHub查阅资料,创建并运行MySQL容器,要求:
① 挂载/tmp/mysql/data到mysql容器内数据存储目录
② 挂载/tmp/mysql/conf/hmy.cnf到mysql容器的配置文件
③ 设置MySQL密码
docker run \
--name some-mysql \
-e MYSQL_ROOT_PASSWORD=root \
-p 3306:3306 \
-v /tmp/mysql/data:/var/lib/mysql \
-v /tmp/mysql/conf/hmy.cnf:/etc/mysql/conf.d/hmy.cnf \
-d mysql:latest
数据卷挂载与目录直接挂载的区别
- 数据卷挂载耦合度低,由docker来管理目录,但是目录较深,不好找
- 目录挂载耦合度高,需要我们自己管理目录,不过目录容易寻找查看
④Dockerfile
常见的镜像在DockerHub就能找到,但是我们自己写的项目就必须自己构建镜像了。
❶镜像结构
要自定义镜像,就必须先了解镜像的结构才行。镜像是将应用程序及其需要的系统函数库、环境、配置、依赖打包而成。
我们以MySQL为例,来看看镜像的组成结构:
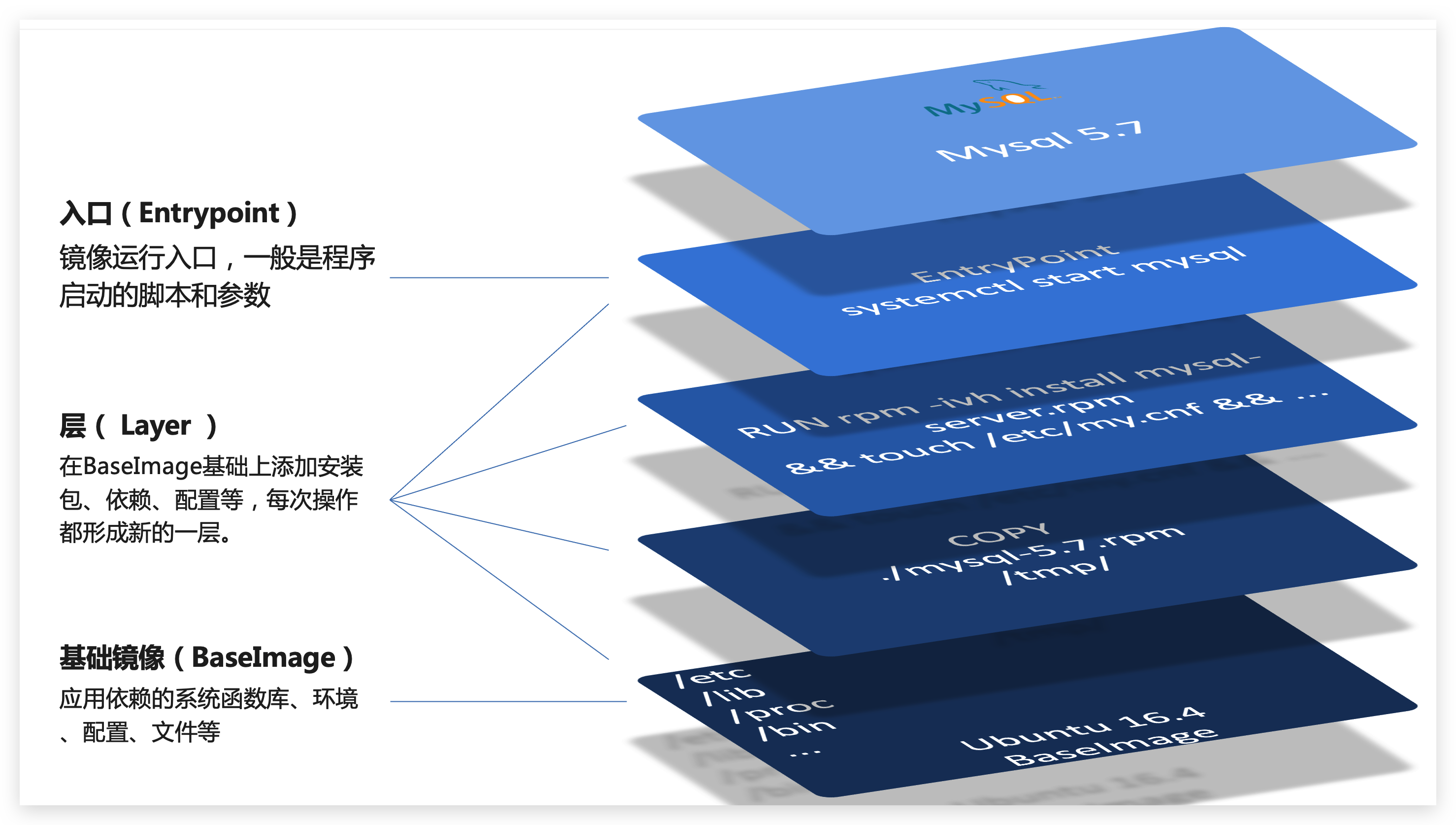
简单来说,镜像就是在系统函数库、运行环境基础上,添加应用程序文件、配置文件、依赖文件等组合,然后编写好启动脚本打包在一起形成的文件。
因此我们只需要告诉Docker,我们的镜像的组成,需要哪些BaseImage、需要拷贝什么文件、需要安装什么依赖、启动脚本是什么,将来Docker会帮助我们构建镜像。而描述这些信息的文件就是Dockerfile文件。
❷语法
Dockerfile就是一个文本文件,其中包含一个个的**指令(Instruction)**,用指令来说明要执行什么操作来构建镜像。每一个指令都会形成一层Layer。

更新详细语法说明,请参考官网文档: https://docs.docker.com/engine/reference/builder
❸案例
⓵基于Ubuntu构建Java项目
需求:基于Ubuntu镜像构建一个新镜像,运行一个java项目
步骤1:新建一个空文件夹 docker-demo
步骤2:拷贝 docker-demo.jar 文件到 docker-demo 目录
步骤3:拷贝 jdk8.tar.gz 文件到 docker-demo 目录
步骤4:在 docker-demo 目录下新建 Dockerfile,内容如下
# 指定基础镜像
FROM ubuntu:16.04
# 配置环境变量,JDK的安装目录
ENV JAVA_DIR=/usr/local
# 拷贝jdk和java项目的包
COPY ./jdk8.tar.gz $JAVA_DIR/
COPY ./docker-demo.jar /tmp/app.jar
# 安装JDK
RUN cd $JAVA_DIR \
&& tar -xf ./jdk8.tar.gz \
&& mv ./jdk1.8.0_144 ./java8
# 配置环境变量
ENV JAVA_HOME=$JAVA_DIR/java8
ENV PATH=$PATH:$JAVA_HOME/bin
# 暴露端口
EXPOSE 8090
# 入口,java项目的启动命令
ENTRYPOINT java -jar /tmp/app.jar
步骤5:进入 docker-demo,运行命令
docker build -t javaweb:1.0 .
# -t代表tag即名字
# .代表Dockerfile所在的目录
步骤6:使用docker run创建容器并运行
docker run --name web -p 8090:8090 -d javaweb:1.0
最后访问 http://127.0.0.1:8090/hello/count
⓶基于java8构建Java项目
虽然我们可以基于Ubuntu基础镜像,添加任意自己需要的安装包,构建镜像,但是却比较麻烦。所以大多数情况下,我们都可以在一些安装了部分软件的基础镜像上做改造。例如,构建java项目的镜像,可以在已经准备了JDK的基础镜像基础上构建。
需求:基于java:8-alpine镜像,将一个Java项目构建为镜像
① 新建一个空文件夹 docker-demo
② 拷贝 docker-demo.jar 到这个目录中
③ 在目录中新建 Dockerfile 文件,内容如下:
FROM java:8-alpine
COPY ./docker-demo.jar /tmp/app.jar
EXPOSE 8090
ENTRYPOINT java -jar /tmp/app.jar
- ④ 使用docker build命令构建镜像
docker build -t javaweb:2.0 .
- ⑤ 使用docker run创建容器并运行
docker run --name web -p 8090:8090 -d javaweb:2.0
⑤DockerCompose
❶简介
在线上环境中,通常不会将项目的所有组件放到同一个容器中;更好的做法是把每个独立的功能装进单独的容器,这样方便复用。因此同一个服务器上会运行着多个容器,如果每次都靠一条条指令去启动,未免也太繁琐了。 Docker-compose 就是解决这个问题的,它用来编排多个容器,将启动容器的命令统一写到 docker-compose.yml 文件中,以后每次启动这一组容器时,只需要 docker-compose up 就可以了。
其实DockerCompose文件可以看做是将多个docker run命令写到一个文件,只是语法稍有差异。
Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。格式如下:
version: "3.8"
services:
mysql:
image: mysql:5.7.25
environment:
MYSQL_ROOT_PASSWORD: root
volumes:
- "/tmp/mysql/data:/var/lib/mysql"
- "/tmp/mysql/conf/hmy.cnf:/etc/mysql/conf.d/hmy.cnf"
web:
build: .
ports:
- "8090:8090"
上面的Compose文件就描述一个项目,其中包含两个容器:
- mysql:一个基于
mysql:5.7.25镜像构建的容器,并且挂载了两个目录 - web:一个基于
docker build临时构建的镜像容器,映射端口时8090
DockerCompose的详细语法参考官网:https://docs.docker.com/compose/compose-file/
❷案例:部署微服务集群
需求:将之前学习的cloud-demo微服务集群利用DockerCompose部署
实现思路:
① 在cloud-demo文件夹编写docker-compose文件
② 修改自己的cloud-demo项目,将数据库、nacos地址都命名为docker-compose中的服务名
③ 使用maven打包工具,将项目中的每个微服务都打包为app.jar
④ 将打包好的app.jar拷贝到cloud-demo中的每一个对应的子目录中
⑤ 将cloud-demo上传至虚拟机,利用 docker-compose up -d 来部署
⓵编写docker-compose文件
version: "3.2" #docker-compose版本
services:
nacos:
image: nacos/nacos-server
environment:
MODE: standalone
ports:
- "8848:8848"
mysql:
image: mysql:5.7.25
environment:
MYSQL_ROOT_PASSWORD: 123
volumes:
- "$PWD/mysql/data:/var/lib/mysql"
- "$PWD/mysql/conf:/etc/mysql/conf.d/"
userservice:
build: ./user-service
orderservice:
build: ./order-service
gateway:
build: ./gateway
ports:
- "10010:10010"
可以看到,其中包含5个service服务:
nacos:作为注册中心和配置中心image: nacos/nacos-server: 基于nacos/nacos-server镜像构建environment:环境变量MODE: standalone:单点模式启动
ports:端口映射,这里暴露了8848端口
mysql:数据库image: mysql:5.7.25:镜像版本是mysql:5.7.25environment:环境变量MYSQL_ROOT_PASSWORD: root:设置数据库root账户的密码为root
volumes:数据卷挂载,这里挂载了mysql的data、conf目录
userservice、orderservice、gateway:都是基于Dockerfile临时构建的
⓶修改微服务配置
因为微服务将来要部署为docker容器,而容器之间互联不是通过IP地址,而是通过容器名。这里我们将order-service、user-service、gateway服务的mysql、nacos地址都修改为基于容器名的访问。如下所示:
spring:
datasource:
url: jdbc:mysql://mysql:3306/cloud_order?useSSL=false # mysql
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
application:
name: orderservice
cloud:
nacos:
server-addr: nacos:8848 # nacos服务地址
⓷打包微服务模块
将每个微服务都打包。因为之前查看到Dockerfile中的jar包名称都是app.jar,因此我们的每个微服务都需要用这个名称。可以通过修改pom.xml中的打包名称来实现,每个微服务都需要修改
<build>
<!-- 服务打包的最终名称 -->
<finalName>app</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
⓸编写Dockerfile
将每个微服务构建成镜像,编写三个Dockerfile,放入对应目录
FROM java:8-alpine
COPY ./app.jar /tmp/app.jar
ENTRYPOINT java -jar /tmp/app.jar
编译打包好的app.jar文件,需要放到Dockerfile的同级目录中。注意:每个微服务的app.jar放到与服务名称对应的目录,别搞错了。
.
├── docker-compose.yml
├── gateway
│ ├── Dockerfile
│ └── app.jar
├── mysql
│ ├── conf
│ └── data
├── order-service
│ ├── Dockerfile
│ └── app.jar
└── user-service
├── Dockerfile
└── app.jar
⓹部署
最后,我们需要将整个cloud-demo文件夹上传到虚拟机中,由DockerCompose部署。
进入cloud-demo目录,然后运行下面的命令:
docker-compose up -d # 后台运行容器
其它命令
docker-compose build # 重新构建镜像
docker-compose start # 启动已有的容器
docker-compose stop # 停止已有的容器
docker-compose logs # 查看容器日志
docker-compose down # 删除容器
⑥私有仓库
使用DockerCompose部署带有图象界面的DockerRegistry,命令如下:
version: '3.0'
services:
registry:
image: registry
volumes:
- ./registry-data:/var/lib/registry
ui:
image: joxit/docker-registry-ui:static
ports:
- 8080:80
environment:
- REGISTRY_TITLE=简简私有仓库
- REGISTRY_URL=http://registry:5000
depends_on:
- registry
❶配置Docker信任地址
我们的私服采用的是http协议,默认使用HTTPS推送镜像,http不被Docker信任,所以需要做一个配置
# 打开要修改的文件
vi /etc/docker/daemon.json
# 添加内容:
"insecure-registries":["http://192.168.150.101:8080"]
# 重加载
systemctl daemon-reload
# 重启docker
systemctl restart docker
访问http://192.168.150.101:8080 即可
❷推送、拉取镜像
推送镜像到私有镜像服务必须先tag,步骤如下:
① 重命名本地镜像,名称前缀为私有仓库的地址:192.168.150.101:8080/
docker tag nginx:latest 192.168.150.101:8080/nginx:1.0
② 推送镜像
docker push 192.168.150.101:8080/nginx:1.0
③ 拉取镜像
docker pull 192.168.150.101:8080/nginx:1.0
9.RabbitMQ
①初识MQ
❶同步和异步
同步通讯:就像打电话,需要实时响应。
异步通讯:就像发微信,不需要马上回复。
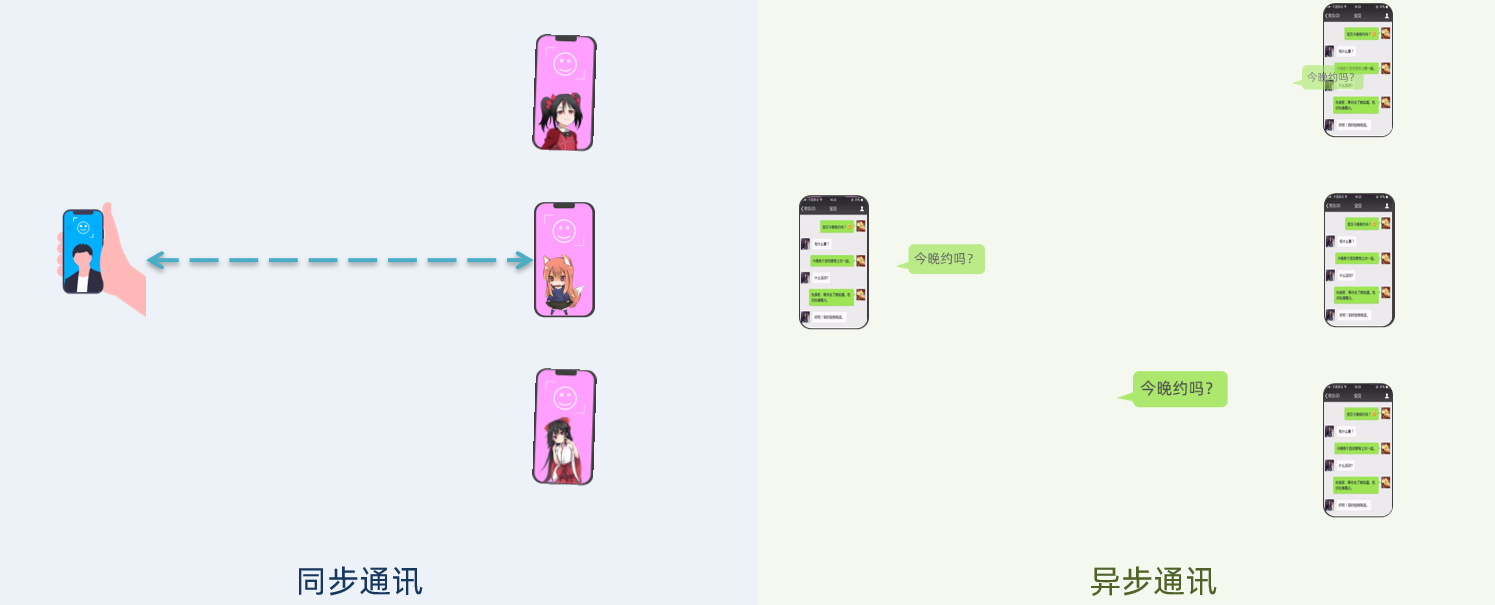
两种方式各有优劣,打电话可以立即得到响应,但是你却不能跟多个人同时通话。发送微信可以同时与多人交流,但是往往响应会有延迟。
同步通讯
优点:
- 时效性较强,可以立即得到结果
缺点:
- 耦合度高
- 性能和吞吐能力下降
- 有额外的资源消耗
- 有级联失败问题
异步通讯
为了解除事件发布者与接收者之间的耦合,两者并不是直接通信,而是有一个中间人(Broker)。发布者发布事件到Broker,不关心谁来订阅事件。接收者从Broker订阅事件,不关心谁发来的消息。

Broker 是一个像数据总线一样的东西,所有的服务要接收数据和发送数据都发到这个总线上,这个总线就像协议一样,让服务间的通讯变得标准和可控。
优点:
吞吐量提升:无需等待接收者处理完成,响应更快速
故障隔离:服务没有直接调用,不存在级联失败问题
调用间没有阻塞,不会造成无效的资源占用
耦合度极低:每个服务都可以灵活插拔,可替换
流量削峰:不管发布事件的流量波动多大,都由Broker接收,接收者可以按照自己的速度去处理事件
缺点:
- 架构复杂了,业务没有明显的流程线,不好管理
- 需要依赖于Broker的可靠、安全、性能
❷消息队列MQ
比较常见的一种 Broker 就是 MQ 技术,中文是消息队列(MessageQueue),字面来看就是存放消息的队列。
比较常见的MQ实现:ActiveMQ、RabbitMQ、RocketMQ、Kafka
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 维护者 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
❸RabbitMQ结构
| MQ成员 | 描述 |
|---|---|
| publisher | 生产者 |
| consumer | 消费者 |
| exchange | 交换机,负责消息路由 |
| queue | 队列,存储消息 |
| virtualHost | 虚拟主机,隔离不同租户的 exchange、queue |

❹RabbitMQ消息模型
RabbitMQ官方提供了5个不同的Demo示例,对应了不同的消息模型
- 基本消息队列(BasicQueue)
- 工作消息队列(WorkQueue)
- 发布订阅模式(Publish/Subscribe)
- 广播(Fanout Exchange)
- 路由(Direct Exchange)
- 主题(Topic Exchange)
②快速入门
❶安装RabbitMQ
- 拉取镜像
docker pull rabbitmq:3-management
- 运行镜像
docker run \
-e RABBITMQ_DEFAULT_USER=jianjian \
-e RABBITMQ_DEFAULT_PASS=123321 \
--name mq \
--hostname mq1 \
-p 15672:15672 \
-p 5672:5672 \
-d rabbitmq:3-management
访问 http://127.0.0.1:15672 即可
❷入门案例
基本消息队列模式的模型图:

官方的HelloWorld是基于最基础的消息队列模型来实现的,只包括三个角色:
- publisher:消息发布者,将消息发送到队列queue
- queue:消息队列,负责接受并缓存消息
- consumer:订阅队列,处理队列中的消息
⓵准备工作
IDEA中导入Demo工程 mq-demo,导入后结构如下:

包括三部分:
- mq-demo:父工程,管理项目依赖
- publisher:消息的发送者
- consumer:消息的消费者
⓶publisher实现
思路:
- 1.建立连接
- 2.创建Channel
- 3.声明队列
- 4.发送消息
- 5.关闭连接和通道
public class PublisherTest {
@Test
public void testSendMessage() throws IOException, TimeoutException {
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.50.86");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("jianjian");
factory.setPassword("123321");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.发送消息
String message = "hello, rabbitmq!";
channel.basicPublish("", queueName, null, message.getBytes());
System.out.println("发送消息成功:【" + message + "】");
// 5.关闭通道和连接
channel.close();
connection.close();
}
}
⓷consumer实现
思路:
- 1.建立连接
- 2.创建Channel
- 3.声明队列
- 4.订阅消息
- 5.处理消息
public class ConsumerTest {
public static void main(String[] args) throws IOException, TimeoutException {
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.50.86");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("jianjian");
factory.setPassword("123321");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.订阅消息
channel.basicConsume(queueName, true, new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
// 5.处理消息
String message = new String(body);
System.out.println("接收到消息:【" + message + "】");
}
});
System.out.println("等待接收消息。。。。");
}
}
⓸总结
基本消息队列的消息发送流程:
建立connection
创建channel
利用channel声明队列
利用channel向队列发送消息
基本消息队列的消息接收流程:
建立connection
创建channel
利用channel声明队列
定义consumer的消费行为handleDelivery()
利用channel将消费者与队列绑定
③SpringAMQP
➊简介
AMQP(Advanced Message Queuing Protocol)是用于在应用程序之间传递业务消息的开放标准。该协议与语言和平台无关,更符合微服务中独立性的要求。
SpringAMQP 是基于AMQP协议 和 RabbitMQ 封装的一套API规范,提供了模板来发送和接收消息。包含两部分,其中spring- amqp是基础抽象,spring-rabbit是底层的默认实现。并且还利用SpringBoot对其实现了自动装配,使用起来非常方便。SpringAMQP的官方地址:https://spring.io/projects/spring-amqp
SpringAMQP提供了三个功能:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消息
➋Basic Queue
⓵准备工作
在父工程mq-demo中引入依赖
<!--AMQP依赖,包含RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
⓶消息发送
首先配置MQ地址,在publisher服务的application.yml中添加配置:
spring:
rabbitmq:
host: 127.0.0.1 # 主机名
port: 5672 # 端口
virtual-host: / # 虚拟主机
username: jianjian # 用户名
password: 123321 # 密码
然后在publisher服务中编写测试类SpringAmqpTest,并利用RabbitTemplate实现消息发送:
@SpringBootTest
public class SpringAmqpTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testSimpleQueue() {
// 队列名称
String queueName = "simple.queue";
// 消息
String message = "hello, spring amqp!";
// 发送消息
rabbitTemplate.convertAndSend(queueName, message);
}
}
⓷消息接收
首先配置MQ地址,在consumer服务的application.yml中添加配置:
spring:
rabbitmq:
host: 127.0.0.1 # 主机名
port: 5672 # 端口
virtual-host: / # 虚拟主机
username: jianjian # 用户名
password: 123321 # 密码
然后在consumer服务的cn.jianjian.mq.listener包中新建一个类SpringRabbitListener,代码如下:
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueueMessage(String msg) throws InterruptedException {
System.out.println("spring 消费者接收到消息:【" + msg + "】");
}
}
⓸测试
启动consumer服务,然后在publisher服务中运行测试代码,发送MQ消息
➌WorkQueue
Work queues 也被称为 Task queues。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。

当消息处理比较耗时的时候,则生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。此时就可以使用 work 模型,多个消费者共同处理消息处理,速度就能大大提高了。
⓵消息发送
这次我们循环发送,模拟大量消息堆积现象。在publisher服务中的SpringAmqpTest类中添加一个测试方法:
@Test
public void testWorkQueue() throws InterruptedException {
// 队列名称
String queueName = "simple.queue";
// 消息
String message = "hello, message_";
for (int i = 0; i < 50; i++) {
// 发送消息
rabbitTemplate.convertAndSend(queueName, message + i);
Thread.sleep(20);// 避免发送太快
}
}
⓶消息接收
要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法:
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {
System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(20);//模拟任务耗时
}
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(200);
}
⓷测试
启动ConsumerApplication后,再执行publisher服务中刚刚编写的测试方法testWorkQueue。
可以看到消费者1很快完成了自己的25条消息。消费者2却在缓慢的处理自己的25条消息。
也就是说消息是平均分配给每个消费者,并没有考虑到消费者的处理能力。这样显然是有问题的。
⓸消费预取限制
通过配置可以解决上述问题。修改consumer服务的application.yml文件,设置preFetch值,可以控制预取消息的上限
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
⓹总结
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量
➍Publish/Subscribe
发布订阅模式的区别就是允许将同一消息发送给多个消费者。实现方式是加入了exchange(交换机)。

- Publisher:生产者,也就是要发送消息的程序,但是不再发送到队列中,而是发给交换机
- Consumer:消费者,与以前一样,订阅队列,没有变化
- Queue:消息队列也与以前一样,接收消息、缓存消息。
- Exchange:交换机,一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。Exchange有以下3种类型:
- Fanout:广播,将消息交给所有绑定到交换机的队列
- Direct:定向,把消息交给符合指定routing key 的队列
- Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
➀Fanout
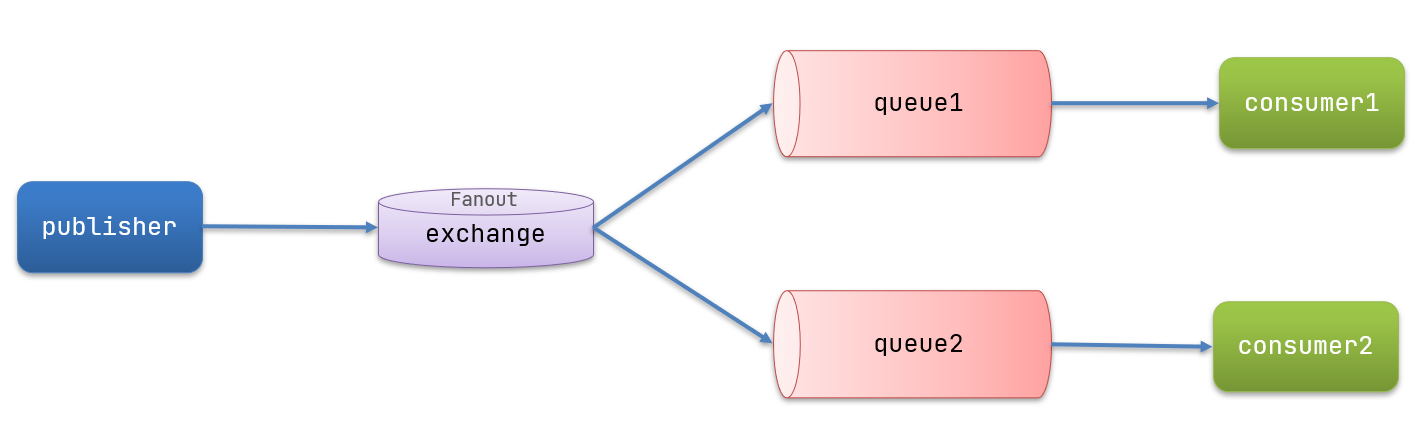
在广播模式下,消息发送流程是这样的:
- 1) 可以有多个队列
- 2) 每个队列都要绑定到 exchange(交换机)
- 3) 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定
- 4) 交换机把消息发送给绑定过的所有队列
- 5) 订阅队列的消费者都能拿到消息
案例
- 创建一个交换机 jianjian.fanout,类型是 Fanout
- 创建两个队列fanout.queue1和fanout.queue2,绑定到交换机 jianjian.fanout
➀声明队列和交换机
Spring提供了一个接口Exchange,来表示所有不同类型的交换机:
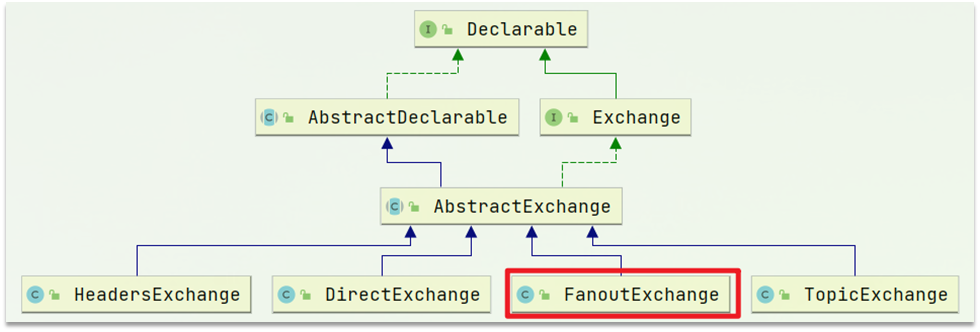
在consumer中创建一个类,声明队列和交换机:
@Configuration
public class FanoutConfig {
/**
* 声明交换机
* @return Fanout类型交换机
*/
@Bean
public FanoutExchange fanoutExchange(){
return new FanoutExchange("jianjian.fanout");
}
/**
* 第1个队列
*/
@Bean
public Queue fanoutQueue1(){
return new Queue("fanout.queue1");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
/**
* 第2个队列
*/
@Bean
public Queue fanoutQueue2(){
return new Queue("fanout.queue2");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue2(Queue fanoutQueue2, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
}
}
➁消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
@Test
public void testFanoutExchange() {
// 队列名称
String exchangeName = "jianjian.fanout";
// 消息
String message = "hello, everyone!";
rabbitTemplate.convertAndSend(exchangeName, "", message);
}
➂消息接收
在consumer服务的SpringRabbitListener中添加两个方法,作为消费者:
@RabbitListener(queues = "fanout.queue1")
public void listenFanoutQueue1(String msg) {
System.out.println("消费者1接收到Fanout消息:【" + msg + "】");
}
@RabbitListener(queues = "fanout.queue2")
public void listenFanoutQueue2(String msg) {
System.out.println("消费者2接收到Fanout消息:【" + msg + "】");
}
➃总结
交换机的作用是什么?
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange会将消息路由到每个绑定的队列
声明队列、交换机、绑定关系的Bean是什么?
- Queue
- FanoutExchange
- Binding
➁Direct
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的exchange。
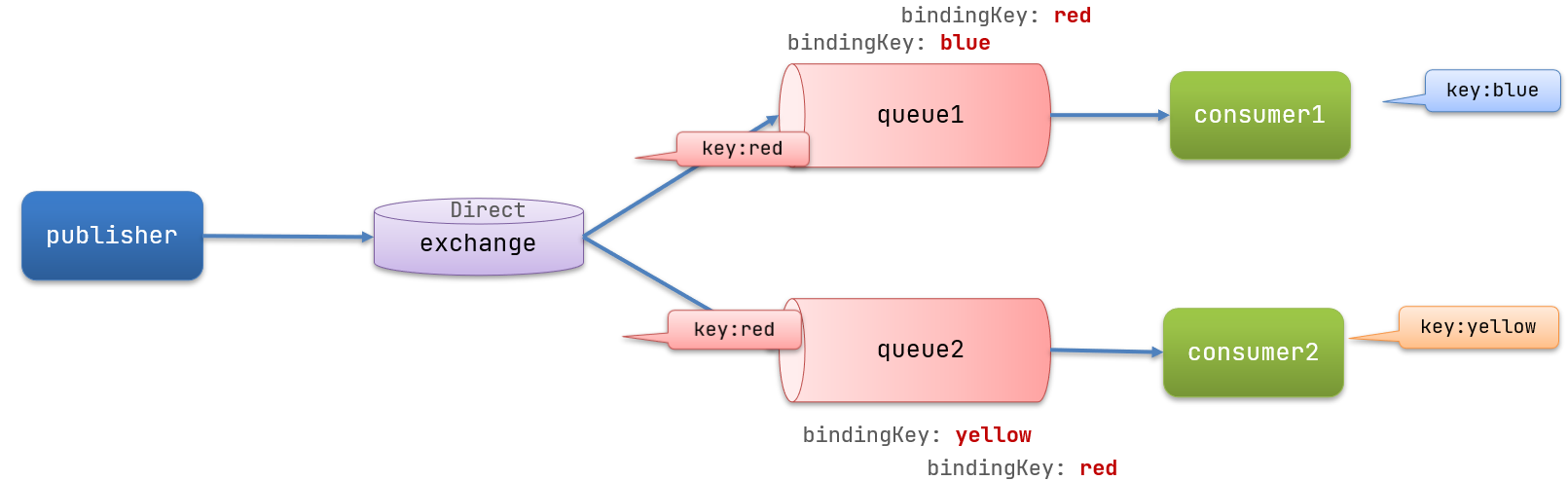
在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) - 消息的发送方在向 exchange发送消息时,也必须指定消息的
RoutingKey。 - exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
案例
利用@RabbitListener声明Exchange、Queue、RoutingKey
在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2
在publisher中编写测试方法,向jianjian. direct发送消息
➀基于注解声明队列和交换机
基于@Bean的方式声明队列和交换机比较麻烦,Spring还提供了基于注解方式来声明。
在consumer的SpringRabbitListener中添加两个消费者,同时基于注解来声明队列和交换机:
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "jianjian.direct", type = ExchangeTypes.DIRECT),
key = {"red", "blue"}
))
public void listenDirectQueue1(String msg){
System.out.println("消费者接收到direct.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue2"),
exchange = @Exchange(name = "jianjian.direct", type = ExchangeTypes.DIRECT),
key = {"red", "yellow"}
))
public void listenDirectQueue2(String msg){
System.out.println("消费者接收到direct.queue2的消息:【" + msg + "】");
}
➁消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
@Test
public void testSendDirectExchange() {
// 交换机名称
String exchangeName = "jianjian.direct";
// 消息
String message = "红色警报!日本乱排核废水,导致海洋生物变异,惊现哥斯拉!";
// 发送消息
rabbitTemplate.convertAndSend(exchangeName, "red", message);
}
➂总结
描述下Direct交换机与Fanout交换机的差异?
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
基于@RabbitListener注解声明队列和交换机有哪些常见注解?
- @Queue
- @Exchange
➂Topic
Topic与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型exchange可以让队列在绑定Routing key 的时候使用通配符!
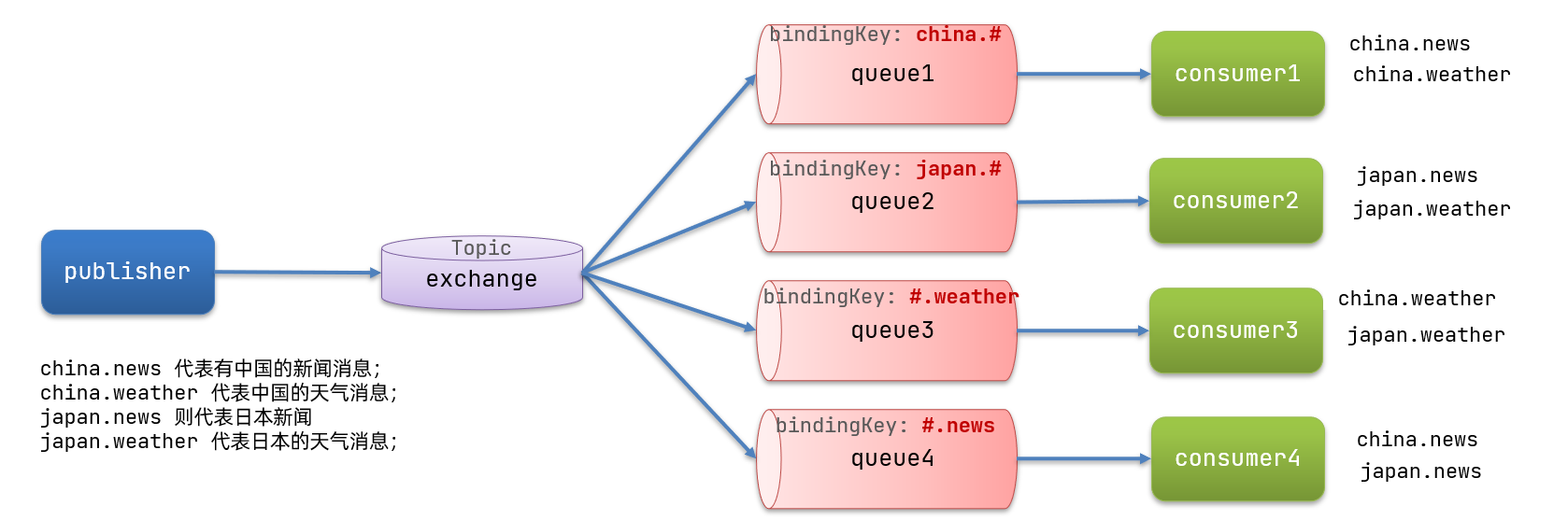
Routingkey 一般都是由一个或多个单词组成,多个单词之间以“.”分割,例如: item.insert
通配符规则:
#:匹配一个或多个词*:匹配不多不少恰好1个词
举例:
item.#:能够匹配item.spu.insert 或者 item.spu
item.*:只能匹配item.spu
解释:
- Queue1:绑定的是
china.#,因此凡是以china.开头的routing key都会被匹配到。包括china.news和china.weather - Queue2:绑定的是
#.news,因此凡是以.news结尾的routing key都会被匹配。包括china.news和japan.news
案例
并利用@RabbitListener声明Exchange、Queue、RoutingKey
在consumer服务中,编写两个消费者方法,分别监听topic.queue1和topic.queue2
在publisher中编写测试方法,向jianjian. topic发送消息
➀消息发送
在publisher服务的SpringAmqpTest类中添加测试方法:
@Test
public void testSendTopicExchange() {
// 交换机名称
String exchangeName = "itcast.topic";
// 消息
String message = "喜报!孙悟空大战哥斯拉,胜!";
// 发送消息
rabbitTemplate.convertAndSend(exchangeName, "china.news", message);
}
➁消息接收
在consumer服务的SpringRabbitListener中添加方法:
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue1"),
exchange = @Exchange(name = "jianjian.topic", type = ExchangeTypes.TOPIC),
key = "china.#"
))
public void listenTopicQueue1(String msg){
System.out.println("消费者接收到topic.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue2"),
exchange = @Exchange(name = "jianjian.topic", type = ExchangeTypes.TOPIC),
key = "#.news"
))
public void listenTopicQueue2(String msg){
System.out.println("消费者接收到topic.queue2的消息:【" + msg + "】");
}
➂总结
描述下Direct交换机与Topic交换机的差异?
- Topic交换机接收的消息RoutingKey必须是多个单词,以
.分割 - Topic交换机与队列绑定时的bindingKey可以指定通配符
#:代表0个或多个词*:代表1个词
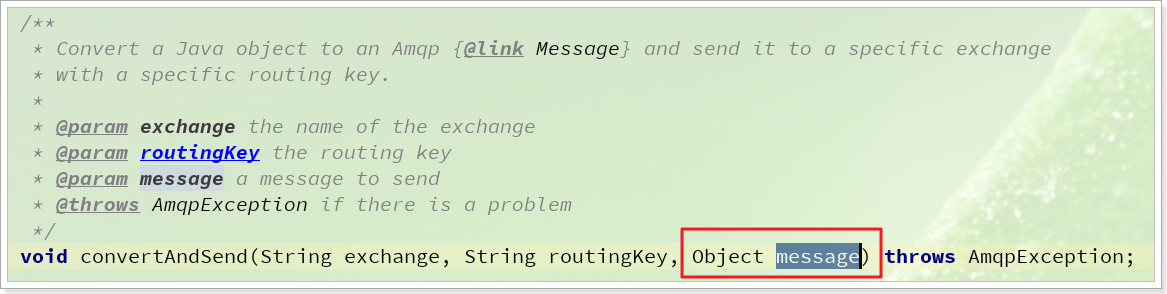
➑消息转换器
Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象。
只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题:
- 数据体积过大
- 有安全漏洞
- 可读性差
➀测试默认转换器
我们修改消息发送的代码,发送一个Map对象:
@Test
public void testSendMap() throws InterruptedException {
// 准备消息
Map<String,Object> msg = new HashMap<>();
msg.put("name", "Jack");
msg.put("age", 21);
// 发送消息
rabbitTemplate.convertAndSend("simple.queue","", msg);
}
发送消息后查看控制台,可以看到消息很长,可读性差。
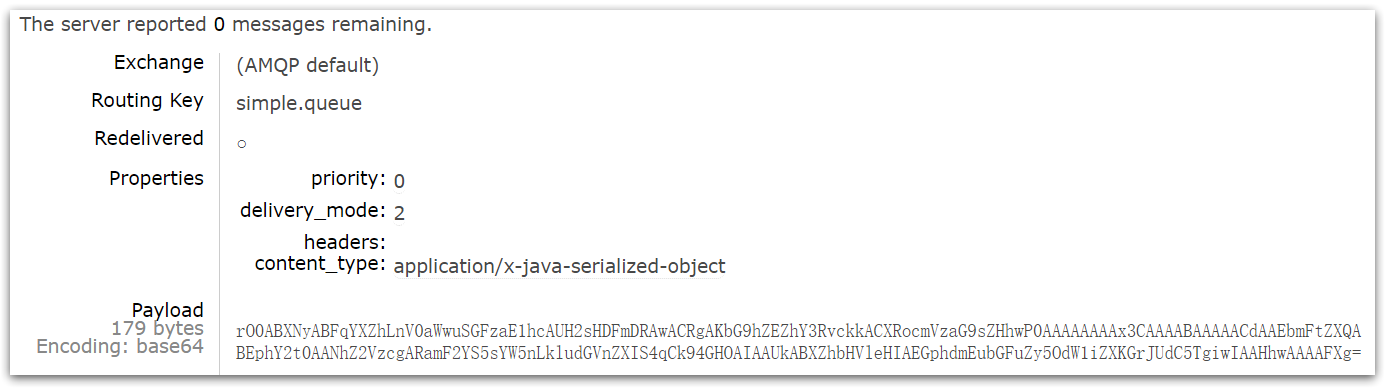
➁配置JSON转换器
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。
在publisher和consumer两个服务中都引入jackson依赖:
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.9.10</version>
</dependency>
配置消息转换器,在启动类中添加一个Bean即可:
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}
10.elasticsearch
Sponsor❤️
您的支持是我不断前进的动力,如果您感觉本文对您有所帮助的话,可以考虑打赏一下本文,用以维持本博客的运营费用,拒绝白嫖,从你我做起!🥰🥰🥰
| 支付宝 | 微信 |
 |
 |



