[SWPU2019]easyRE
main函数:
int __cdecl main(int argc, const char **argv, const char **envp)
{
_DWORD v4[28]; // [esp-6Ch] [ebp-F8h] BYREF
_DWORD *v5; // [esp+4h] [ebp-88h]
_DWORD *v6; // [esp+8h] [ebp-84h]
int v7; // [esp+Ch] [ebp-80h]
char v8[108]; // [esp+10h] [ebp-7Ch] BYREF
int v9; // [esp+88h] [ebp-4h]
if ( sub_40EF90() )
return 1;
sub_4026C0(0x6Cu);
sub_401FE0(v4[27], v5);
v9 = 0;
v6 = v4;
sub_40F360(v8);
sub_40F080(v4[0], v4[1]);
v5 = v4;
sub_40F360(v8);
sub_40F150(argc, (int)argv);
v7 = 0;
v9 = -1;
sub_4021C0(v8);
return v7;
}
首先调用sub_40EF90进行check:
BOOL sub_40EF90()
{
HANDLE v0; // eax
NTSTATUS (__stdcall *NtQueryInformationProcess)(HANDLE, PROCESSINFOCLASS, PVOID, ULONG, PULONG); // [esp+0h] [ebp-14h]
HMODULE hModule; // [esp+4h] [ebp-10h]
int v4; // [esp+Ch] [ebp-8h] BYREF
v4 = 0;
hModule = LoadLibraryA("Ntdll.dll");
NtQueryInformationProcess = (NTSTATUS (__stdcall *)(HANDLE, PROCESSINFOCLASS, PVOID, ULONG, PULONG))GetProcAddress(hModule, "NtQueryInformationProcess");
v0 = GetCurrentProcess();
NtQueryInformationProcess(v0, ProcessDebugPort, &v4, 4, 0);
return v4 != 0;
}
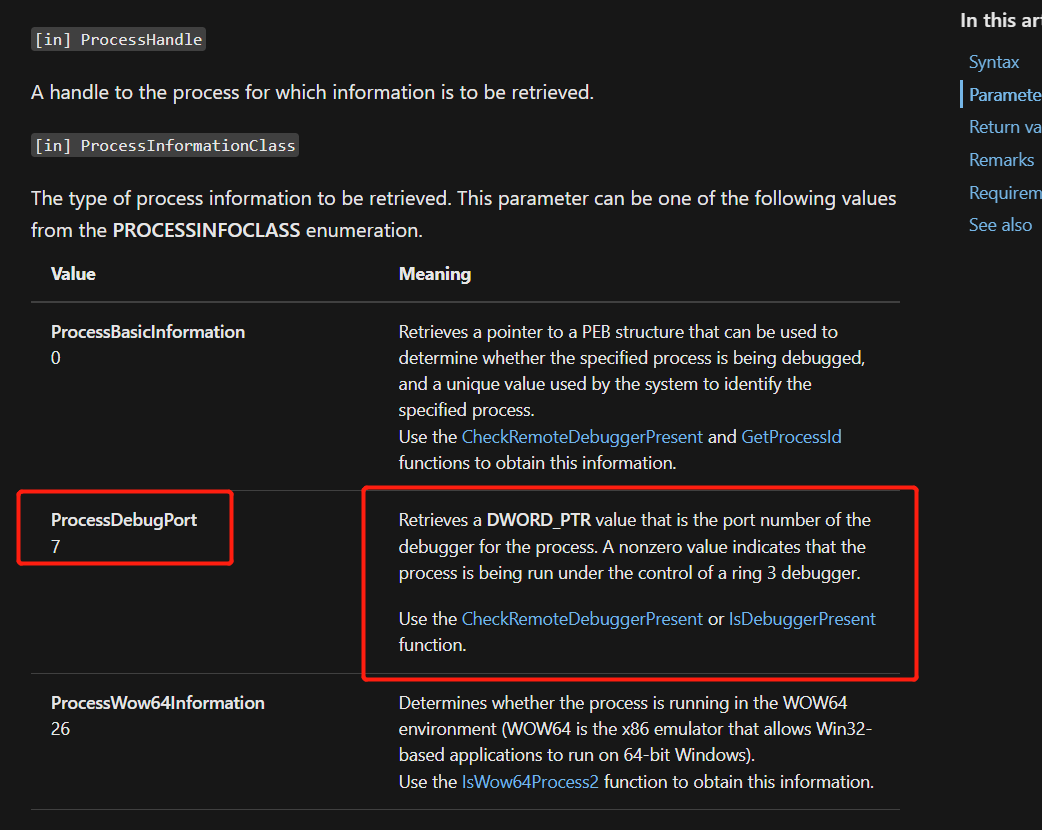
搜了一下官方文档,发现ProcessDebugPort就是用来检测程序是否处于调试状态的:
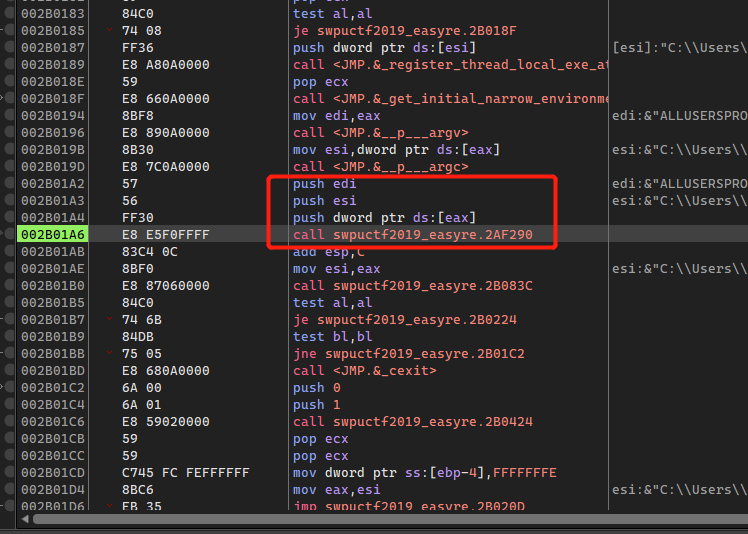
这里crack很简单,动态调试单步来到这个位 置,这里是压入三个参数的,一般就是main函数的入口了:
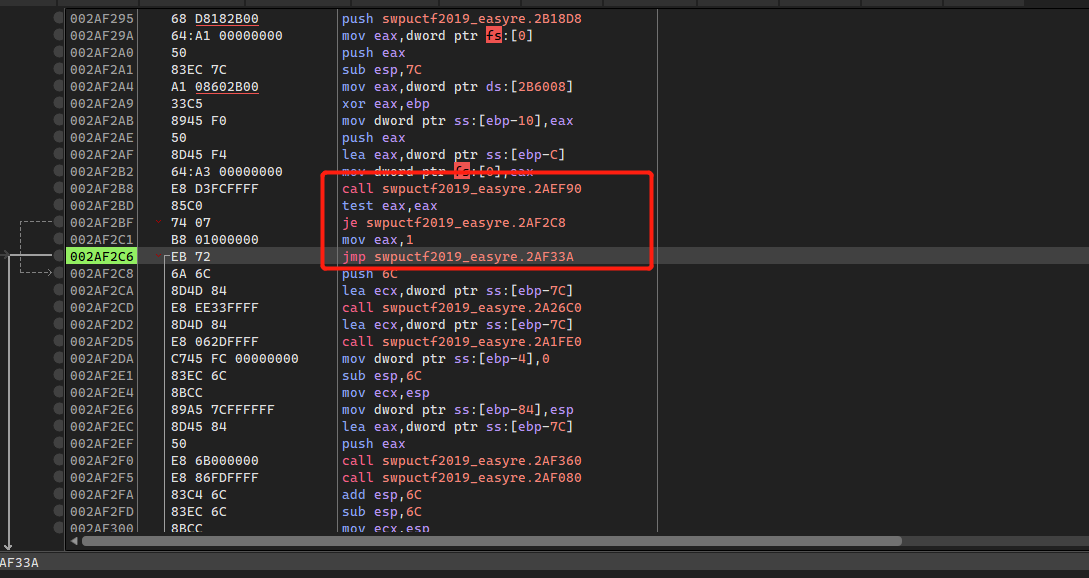
call完EF90之后会有个关键跳,这里jmp实现的话就直接退出程序了,直接nop掉jmp即可:
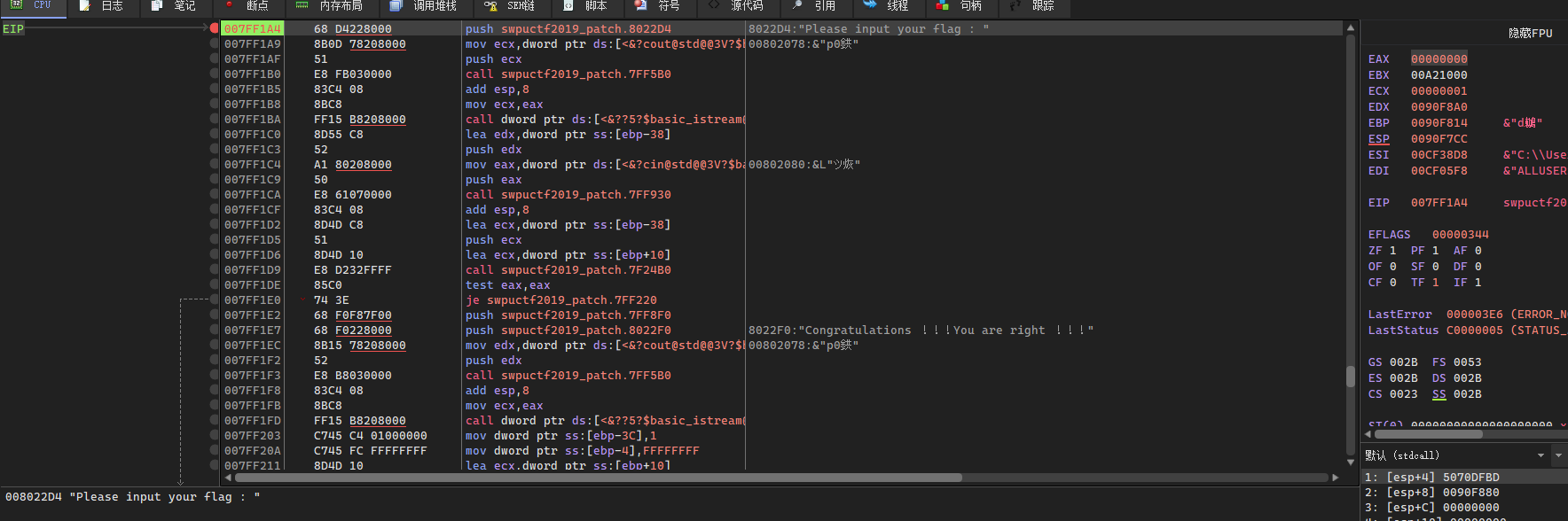
Patch完之后重新载入x64dbg,此时就可以正常调试了:
当然了这个调试状态检测我们是可以绕过的,因为是在检测调试之后再执行真正的代码,所以可以先直接运行程序,然后用附加程序,这时候程序已经运行到输入flag的位置了,附加时已经过了检测函数,所以也可以正常进行调试:
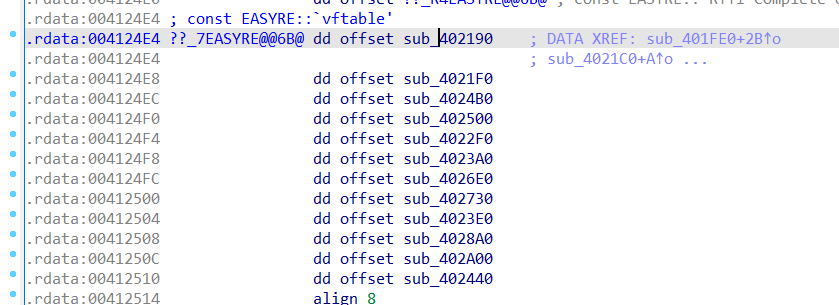
往下来到sub_401FE0,发现有个EASYRE::vftable虚函数表,然后往下对内存进行赋值,总共20个字节,往下还有个内存复制,也是20个字节:
_DWORD *__thiscall sub_401FE0(_DWORD *this)
{
int i; // [esp+4h] [ebp-14h]
*this = &EASYRE::`vftable';
this[1] = 0;
*((_BYTE *)this + 52) = 8;
*((_BYTE *)this + 53) = 0xEA;
*((_BYTE *)this + 54) = 0x58;
*((_BYTE *)this + 55) = 0xDE;
*((_BYTE *)this + 56) = 0x94;
*((_BYTE *)this + 57) = 0xD0;
*((_BYTE *)this + 58) = 0x3B;
*((_BYTE *)this + 59) = 0xBE;
*((_BYTE *)this + 60) = 0x88;
*((_BYTE *)this + 61) = 0xD4;
*((_BYTE *)this + 62) = 0x32;
*((_BYTE *)this + 63) = 0xB6;
*((_BYTE *)this + 64) = 0x14;
*((_BYTE *)this + 65) = 0x82;
*((_BYTE *)this + 66) = 0xB7;
*((_BYTE *)this + 67) = 0xAF;
*((_BYTE *)this + 68) = 0x14;
*((_BYTE *)this + 69) = 0x54;
*((_BYTE *)this + 70) = 0x7F;
*((_BYTE *)this + 71) = 0xCF;
qmemcpy(this + 18, " 03\"3 0 203\" $ ", 20);
sub_4030A0(this + 23);
sub_402DE0(this + 26);
for ( i = 0; i < 40; ++i )
*((_BYTE *)this + i + 12) = 0;
return this;
}
字符串定位到sub_40F150,传入的flag通过sub_4024B0进行校验,条件成立才能输出Congratulations:
int sub_40F150(int a1, int a2, ...)
{
int v2; // eax
int v3; // eax
int result; // eax
int v5; // eax
int v6[10]; // [esp+Ch] [ebp-38h] BYREF
int v7; // [esp+40h] [ebp-4h]
va_list va; // [esp+54h] [ebp+10h] BYREF
va_start(va, a2);
v7 = 0;
v6[0] = 0;
v6[1] = 0;
v6[2] = 0;
v6[3] = 0;
v6[4] = 0;
v6[5] = 0;
v6[6] = 0;
v6[7] = 0;
v6[8] = 0;
v6[9] = 0;
v2 = sub_40F5B0(std::cout, "Please input your flag : ");
std::ostream::operator<<(v2, sub_40F8F0);
sub_40F930(std::cin, flag);
if ( sub_4024B0(flag) )
{
v3 = sub_40F5B0(std::cout, &unk_4122F0); // Congratulations
std::ostream::operator<<(v3, sub_40F8F0);
v7 = -1;
sub_4021C0(va);
result = 1;
}
else
{
v5 = sub_40F5B0(std::cout, &unk_41231C); // I'm sorry
std::ostream::operator<<(v5, sub_40F8F0);
v7 = -1;
sub_4021C0(va);
result = 0;
}
return result;
}
sub_4024B0,虚函数调用的特征:
BOOL __thiscall sub_4024B0(_DWORD *this, int flag)
{
BOOL result; // eax
this[2] = flag;
result = 0;
if ( (*(int (__thiscall **)(_DWORD *))(*this + 0xC))(this) )
{
(*(void (__thiscall **)(_DWORD *))(*this + 0x18))(this);
if ( (*(int (__thiscall **)(_DWORD *))(*this + 0x28))(this) )
result = 1;
}
return result;
}
根据虚表简化得到:
BOOL __thiscall sub_4024B0(_DWORD *this, int flag)
{
BOOL result; // eax
this[2] = flag;
result = 0;
if ( sub_402500(flag) )
{
sub_4026E0();
if ( sub_402A00() )
result = 1;
}
return result;
}
sub_402500
将字符串Ncg复制到v8然后将v8的值逐个异或0x10:
int __thiscall sub_402500(const char **this)
{
int v2; // [esp+Ch] [ebp-B0h]
unsigned int v3; // [esp+14h] [ebp-A8h]
int i; // [esp+24h] [ebp-98h]
char v6[56]; // [esp+30h] [ebp-8Ch] BYREF
char v7[20]; // [esp+68h] [ebp-54h] BYREF
char v8[48]; // [esp+7Ch] [ebp-40h] BYREF
int v9; // [esp+B8h] [ebp-4h]
v3 = (unsigned int)&this[2][strlen(this[2])];
strcpy(v8, "Ncg`esdvLkLgk$mL=Lgk$mL=Lgk$mL=Lgk$mL=Lgk$mLm");
sub_4026C0(v6, 0x38u);
sub_402B00();
v9 = 0;
for ( i = 0; i < 45; ++i )
v8[i] ^= 0x10u;
sub_4026C0(v7, 0x14u);
sub_402A70(v8, 1);
LOBYTE(v9) = 1;
v2 = (unsigned __int8)sub_404260(this[2], v3, v6, v7, 0);
LOBYTE(v9) = 0;
sub_402A50(v7);
v9 = -1;
sub_4026A0();
return v2;
}
得到一个正则表达式:^swpuctf\\{\\w{4}\\-\\w{4}\\-\\w{4}\\-\\w{4}\\-\\w{4}\\}为flag的格式
s = "Ncg`esdvLkLgk$mL=Lgk$mL=Lgk$mL=Lgk$mL=Lgk$mLm"
s2 = []
for i in range(0, len(s)):
s2.append(chr(ord(s[i]) ^ 0x10))
print(''.join(i for i in s2))
# ^swpuctf\\{\\w{4}\\-\\w{4}\\-\\w{4}\\-\\w{4}\\-\\w{4}\\}
那么可以得到第一个函数就是校验flag的格式,dbg中输入:swpuctf{1234-5678-9012-3456-7890},此时跳转已经不实现:
sub_402A00
先看到最后一个函数,需要让if成立,使得result=1,才能最终输出Congratulations
if ( sub_402A00() )
result = 1;
int __thiscall sub_402A00(unsigned __int8 *this)
{
int i; // [esp+4h] [ebp-4h]
for ( i = 0; i < 40; ++i )
{
if ( this[i + 52] != this[i + 12] )
return 0;
}
return 1;
}
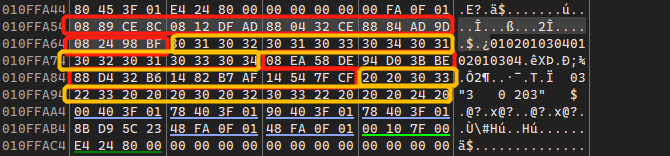
this[52]在sub_401FE0中进行了赋值,需要注意i从0开始经过40次循环,回到sub_401FE0的初始化,发现还存在一个字符串: 03\"3 0 203\" $,说明还存在一个需要比较的结果:
*((_BYTE *)this + 52) = 8;
*((_BYTE *)this + 53) = 0xEA;
*((_BYTE *)this + 54) = 0x58;
*((_BYTE *)this + 55) = 0xDE;
*((_BYTE *)this + 56) = 0x94;
*((_BYTE *)this + 57) = 0xD0;
*((_BYTE *)this + 58) = 0x3B;
*((_BYTE *)this + 59) = 0xBE;
*((_BYTE *)this + 60) = 0x88;
*((_BYTE *)this + 61) = 0xD4;
*((_BYTE *)this + 62) = 0x32;
*((_BYTE *)this + 63) = 0xB6;
*((_BYTE *)this + 64) = 0x14;
*((_BYTE *)this + 65) = 0x82;
*((_BYTE *)this + 66) = 0xB7;
*((_BYTE *)this + 67) = 0xAF;
*((_BYTE *)this + 68) = 0x14;
*((_BYTE *)this + 69) = 0x54;
*((_BYTE *)this + 70) = 0x7F;
*((_BYTE *)this + 71) = 0xCF;
qmemcpy(this + 18, " 03\"3 0 203\" $ ", 20);
sub_4026E0
来到关键的处理函数:
int __thiscall sub_4026E0(void *this)
{
int i; // [esp+4h] [ebp-4h]
for ( i = 0; i < 5; ++i )
(*(void (__thiscall **)(void *, int))(*(_DWORD *)this + 0x1C))(this, i); //
return (*(int (__thiscall **)(void *))(*(_DWORD *)this + 0x24))(this); //
}
同样查表:
this+0x1c -> sub_402730
this+0x24 -> sub_4028A0
int __thiscall sub_402730(_DWORD *this, int a2)
{
int v2; // esi
int v3; // ecx
unsigned __int8 v4; // al
char v6; // cf
char v7; // bl
char v8; // t2
int v10; // [esp+Ch] [ebp-30h]
int i; // [esp+14h] [ebp-28h]
int j; // [esp+1Ch] [ebp-20h]
int v13; // [esp+20h] [ebp-1Ch] BYREF
int v14; // [esp+24h] [ebp-18h]
int v15; // [esp+28h] [ebp-14h]
int v16; // [esp+2Ch] [ebp-10h]
int v17; // [esp+30h] [ebp-Ch]
int v18; // [esp+34h] [ebp-8h]
v13 = 0;
v14 = 0;
v15 = 0;
v16 = 0;
v17 = 0;
v18 = 0;
v10 = this[2] + 5 * a2 + 8; // 根据传入的a2取flag的各个部分
for ( i = 0; i < 4; ++i )
*((_BYTE *)&v13 + i) = *(_BYTE *)(i + v10); // 复制内存
v2 = 0;
v3 = 4;
do
{
v4 = *((_BYTE *)&v13 + v2);
_DL = v4;
__asm { rcl dl, 1 }
*((_BYTE *)&v15 + v2) = 1;
v7 = 0;
v6 = 0;
do
{
v8 = v6 << 7;
v6 = v4 & 1; // 影响循环次数
v4 = (v4 >> 1) | v8;
++v7;
}
while ( v6 );
*((_BYTE *)&v16 + v2++) = v7 - 1;
--v3;
}
while ( v3 );
for ( j = 0; j < 4; ++j )
{
*((_BYTE *)&v14 + j) = *((_BYTE *)&v16 + j) + *((_BYTE *)&v15 + j);
*((_BYTE *)&v17 + j) = *((char *)&v13 + j) << *((_BYTE *)&v15 + j);
*((_BYTE *)&v18 + j) = (*((char *)&v13 + j) << (8 - *((_BYTE *)&v16 + j))) | ((unsigned __int8)(*((char *)&v13 + j) >> (8 - *((_BYTE *)&v15 + j))) << *((_BYTE *)&v15 + j));
}
return sub_402F80(&v13);
}
v10 = this[2] + 5 * a2 + 8;,a2作为下标,通过-分割开取值,此时外层循环中i为0,所以传入的a2也是0,在x64dbg中存储为ecx,所以此时v10指向的就是flag的第一部分1234:
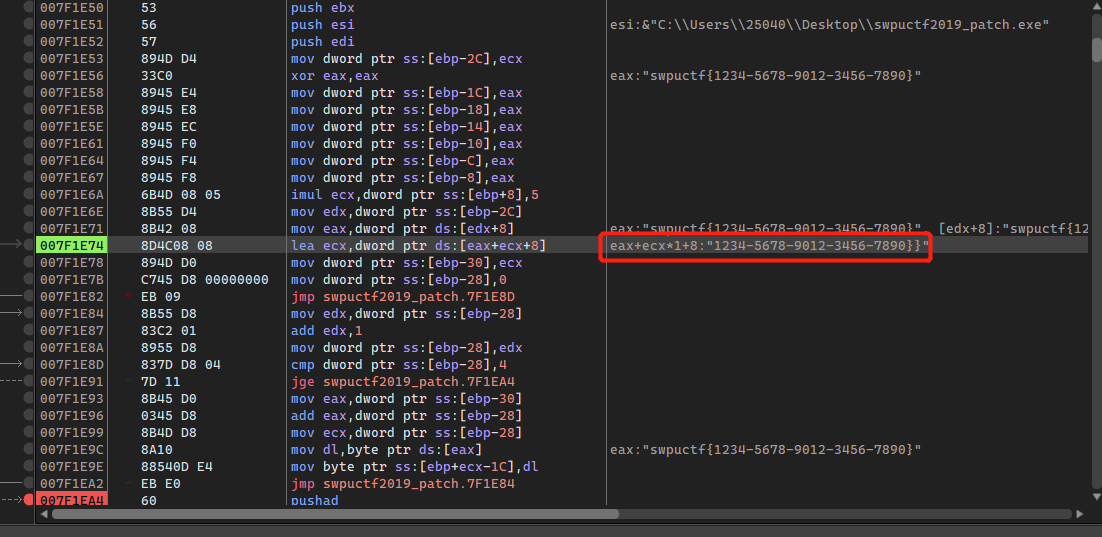
do-while循环中,明显可以看出是针对单字符进行处理的,v2作为索引,每次取一个字符放到v4中,v3作为循环次数,每循环一次减一:
这里只写了rcl dl,1
v2 = 0;
v3 = 4;
do
{
v4 = *((_BYTE *)&v13 + v2); // 取单个字符
_DL = v4;
__asm { rcl dl, 1 } // 循环左移
*((_BYTE *)&v15 + v2) = 1;
v7 = 0;
v6 = 0;
do
{
v8 = v6 << 7;
v6 = v4 & 1; // 影响循环次数
v4 = (v4 >> 1) | v8;
++v7;
}
while ( v6 );
*((_BYTE *)&v16 + v2++) = v7 - 1;
--v3;
}
while ( v3 );
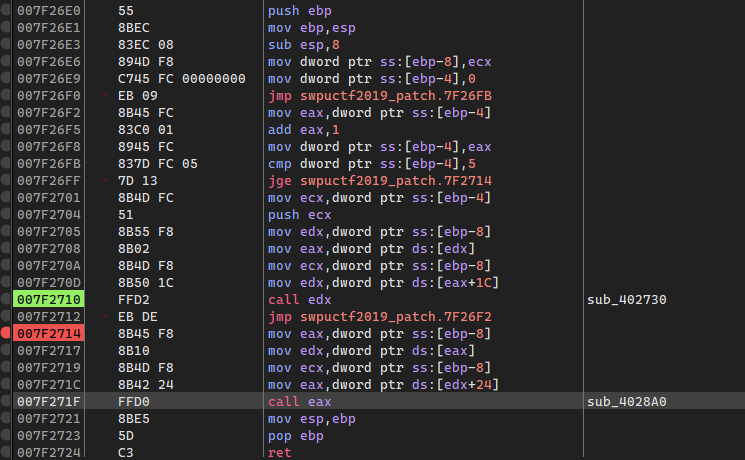
x64dbg调试的时候,可以发现rcl下面存在一个jb指令,这个指令受CF位的影响,当CF为1时跳转指令成立,这里跟dl的值有关,当dl产生进位时CF置1,跳转成立,出循环:
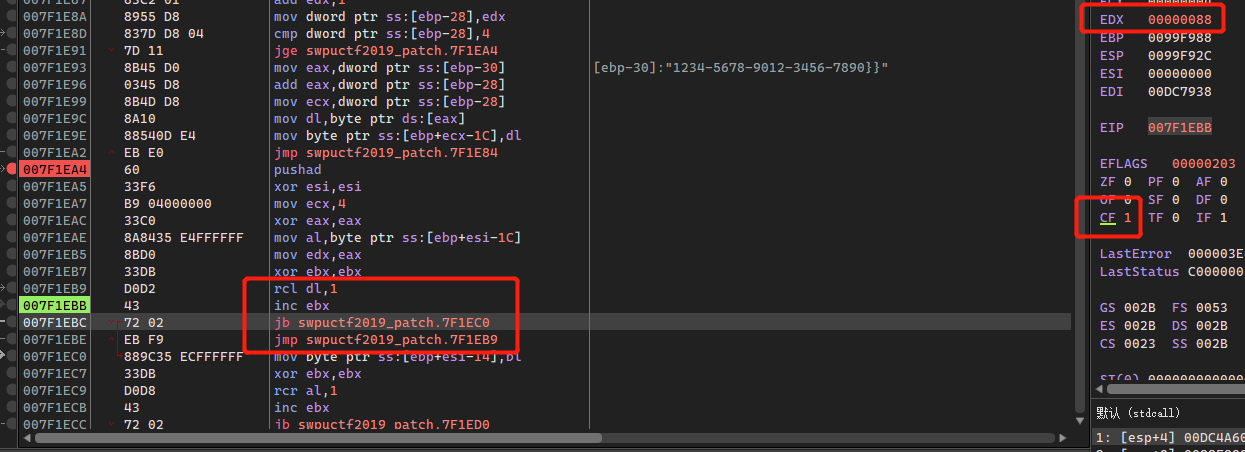
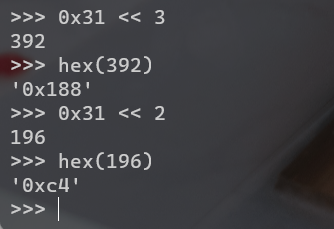
经测试可以发现当0x31左移3次时产生进位,所以此时ebx值为3,那么ebx中记录的就是左移的位数:
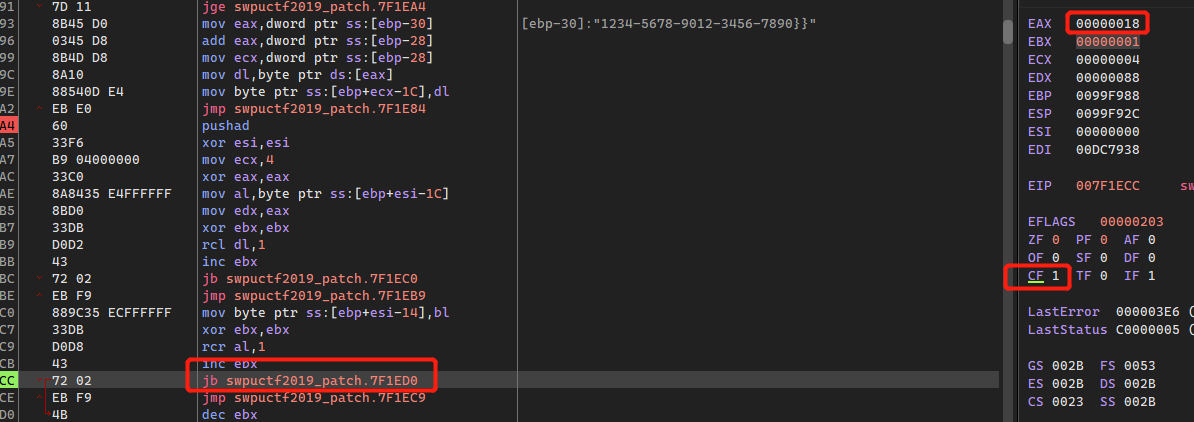
同理,往下对0x31进行右移,当产生进位时CF置1,跳出循环,ebx记录右移次数减一的值:
这一部分在IDA反编译的不太一样,按照动态调试中体现的汇编更容易理解:
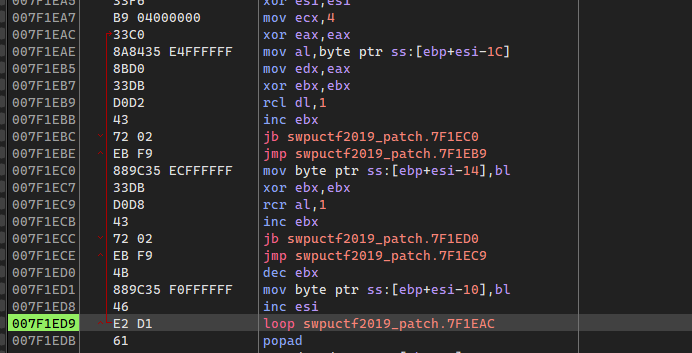
4次循环之后得到,分别对应0x31 0x32 0x33 0x34,左边的为左移到进位的次数;右边为右移次数减一,这么理解比较奇怪,我觉得可以理解为从右边0的个数:
如:0x31,二进制为 0011 0001,所以此时右边0的个数为0
0x32,二进制为 0011 0010,所以此时右边0的个数为1
0x34,二进制为 0011 0100,所以此时右边0的个数为2
![]()
第二个循环:
for ( j = 0; j < 4; ++j )
{
*((_BYTE *)&v14 + j) = *((_BYTE *)&v16 + j) + *((_BYTE *)&v15 + j);
*((_BYTE *)&v17 + j) = *((char *)&v13 + j) << *((_BYTE *)&v15 + j);
*((_BYTE *)&v18 + j) = (*((char *)&v13 + j) << (8 - *((_BYTE *)&v16 + j))) | ((unsigned __int8)(*((char *)&v13 + j) >> (8 - *((_BYTE *)&v15 + j))) << *((_BYTE *)&v15 + j));
}
根据第一个循环简化,最终生成三个值,处理每个字符的结果是独立进行计算的,跟位置和前后字符无关,互不影响:
for ( j = 0; j < 4; ++j )
{
res1 = 右边0的个数 + 左移进位次数;
res2 = flag << 左移进位次数;
res3 = (flag << (8 - 0的个数)) | ((flag >> (8 - 左移次数)) << 左移次数);
}
这里IDA反编译的res2应该是少了一个移位运算,第一步
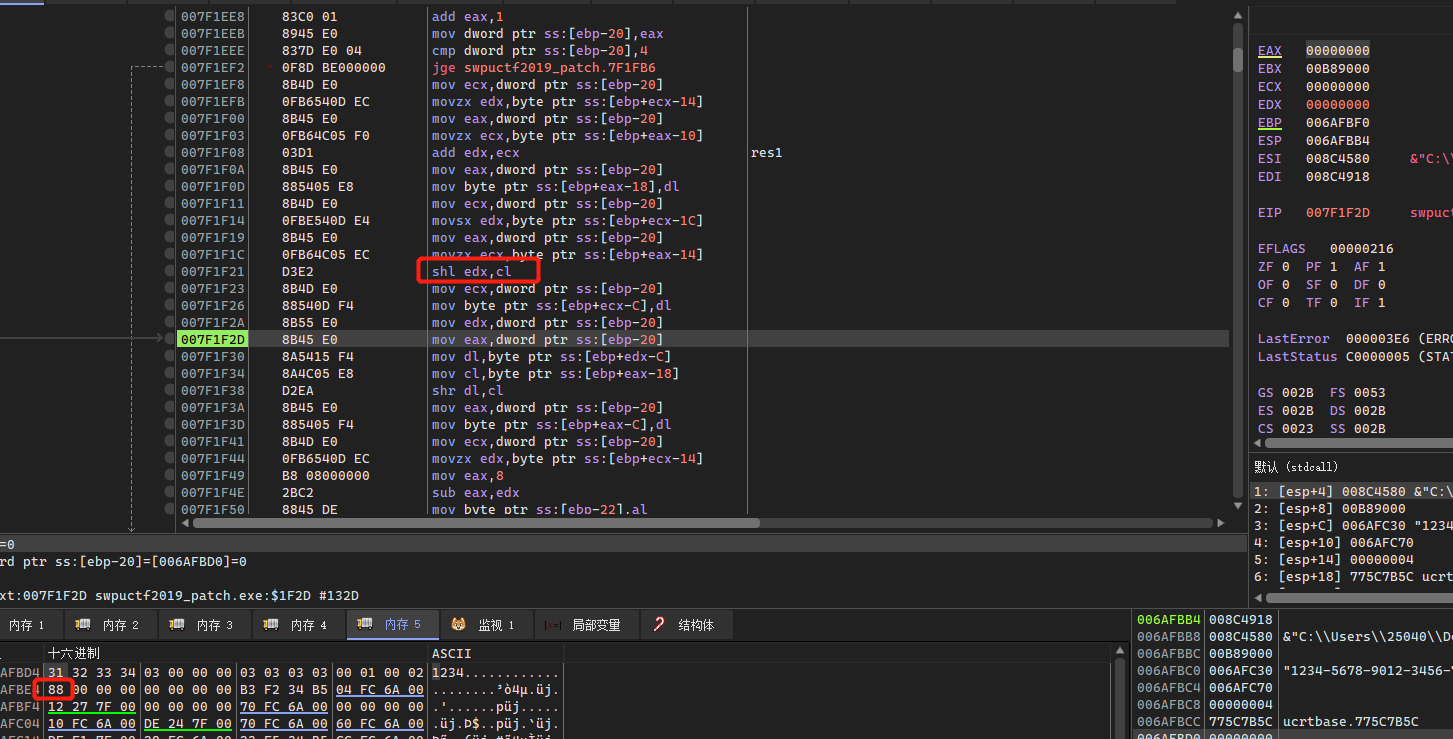
运行之后得到:
往下走到最后一个处理的函数sub_4028A0,存在while循环,这里while循环的条件为sub_402E00传入v2之后的结果,大致理解为flag的结束,说明while循环针对flag进行遍历的,每个while循环对单个字符进行处理,跟之前的处理一样,不受位置和前后字符值的影响:
result = sub_402E00(v2);
if ( !(_BYTE)result )
break;
在while中存在一个for循环,该循环分为上下两部分,前四次循环会对v15和v15+i+20进行运算处理,后四次循环只对v15进行处理,这里sub_402DC0指向处理后的字符以及sub_402730处理后的结果:
for ( i = 0; i < 8; ++i )
{
if ( i >= 4 )
{
v9 = sub_402DC0(v17 + 26);
v14 -= *(unsigned __int8 *)(v9 + i);
v10 = sub_402DC0(v17 + 26);
*v15 |= *(unsigned __int8 *)(v10 + i + 16) << v14;
}
else
{
v4 = sub_402DC0(v17 + 26);
v13 = 8 - *(unsigned __int8 *)(v4 + i + 4);
v14 -= v13;
v5 = sub_402DC0(v17 + 26);
*v15 |= *(unsigned __int8 *)(v5 + i + 16) << v14;
v6 = sub_402DC0(v17 + 26);
v7 = 16 * *(_BYTE *)(v6 + i + 8);
v8 = sub_402DC0(v17 + 26);
*((_BYTE *)v15 + i + 20) = *(_BYTE *)(v8 + i + 12) | v7;
}
}
执行sub_402DC0后返回0xDC41D8:
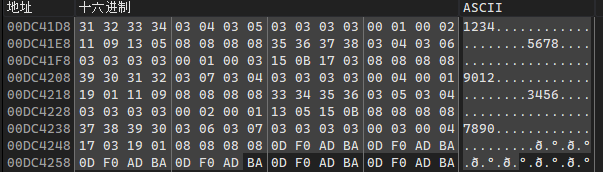
根据0xDC41D8指向的内存,可以简化该循环:
if {
v9 = sub_402DC0(v17 + 26);
v14 -= *(unsigned __int8 *)(v9 + i); // v14的初始值为0x20
*v15 |= res3 << v14;
}
else {
v14 -= 8 - res1;
*v15 |= res2 << v14;
*((_BYTE *)v15 + i + 20) = 0的个数 | (16 * 左移进位位数);
}
可以发现v15 + i + 20是直接赋值,而这里i注意是跟循环有关,那么每个for循环会生成4个值,而v15注意到DWORD指针,每个for循环也是生成一个DWORD类型的数据,可以判断出while循环应该是进行5次,每次对一部分flag进行处理,最终会得到一个长度为40的结果,调用sub_402A00进行比较
第一个循环解决之后得到两个值,顺带发现了最终对比的数据就是前面初始化值的数据
第一个循环:
0x11 << (0x20 - (8 - res1)) = 0x88000000 // 小端存储
0 | (16 * 0x03) = 0x30
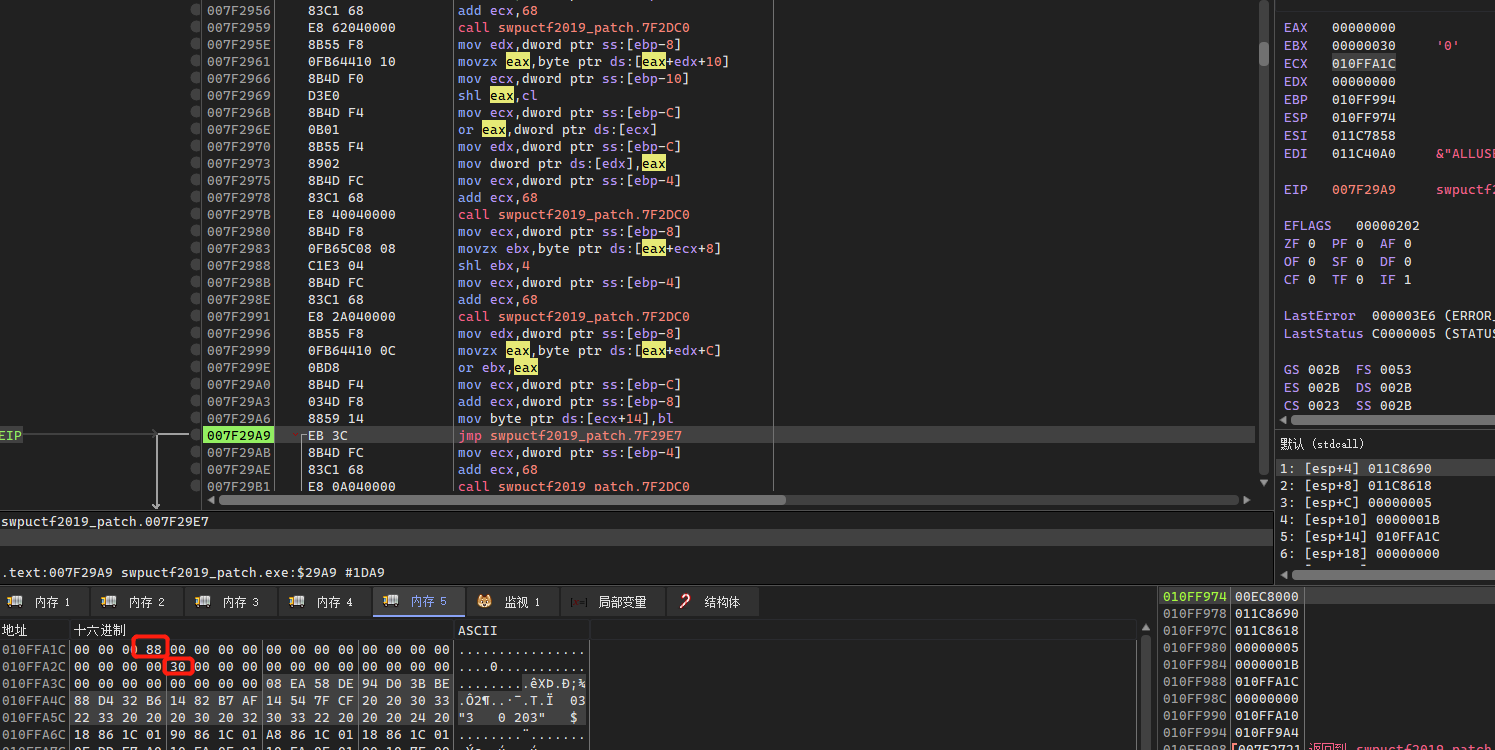
第二次循环结束,发现第一部分是会受其他循环影响的,而第二部分是不受其他循环影响的:
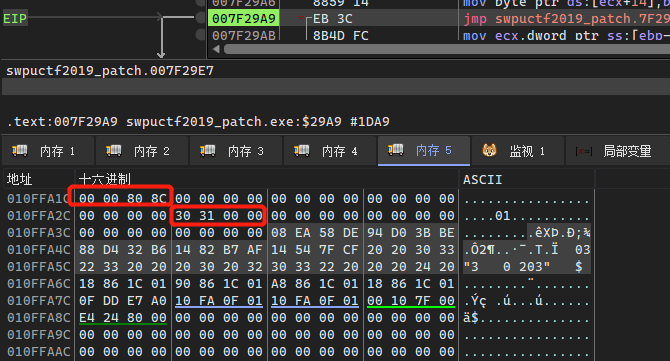
当i>=4时,是直接取res1:
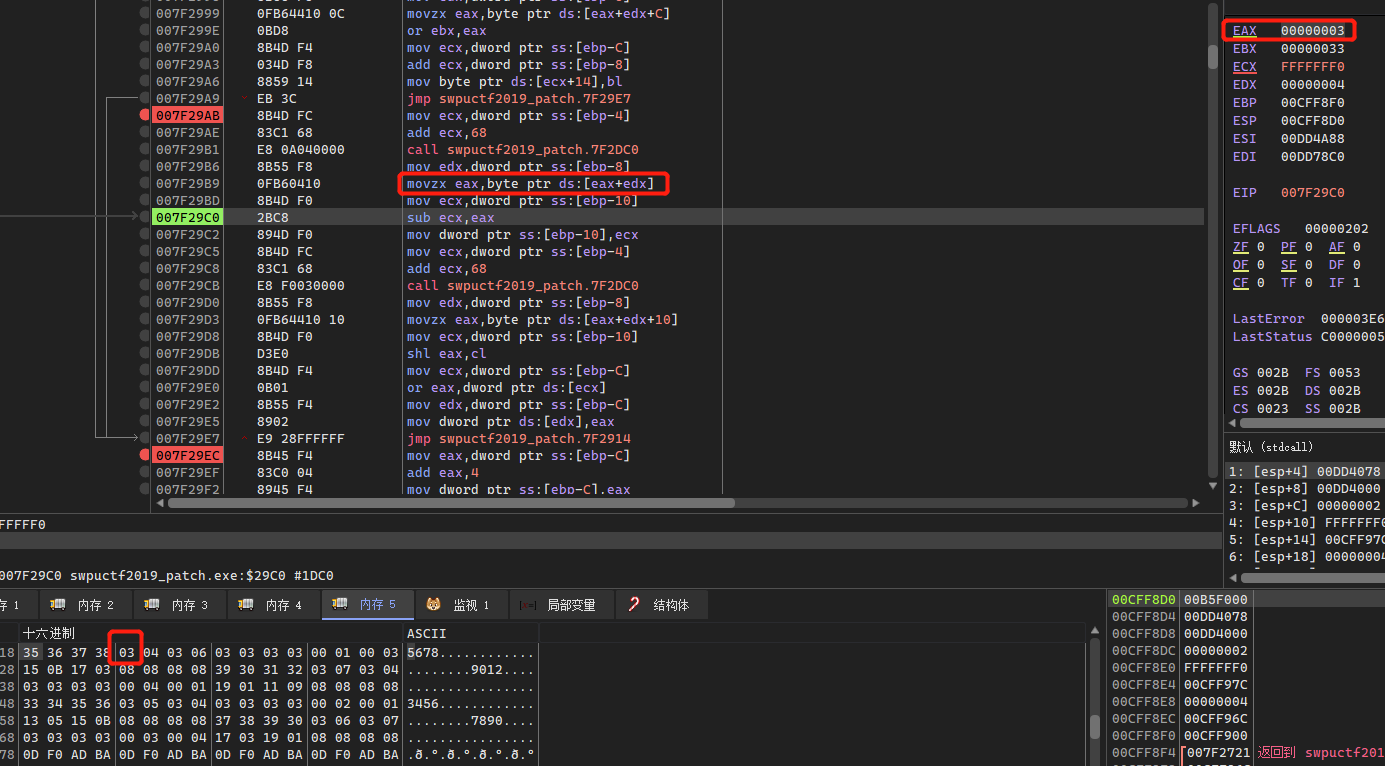
和res2进行运算:
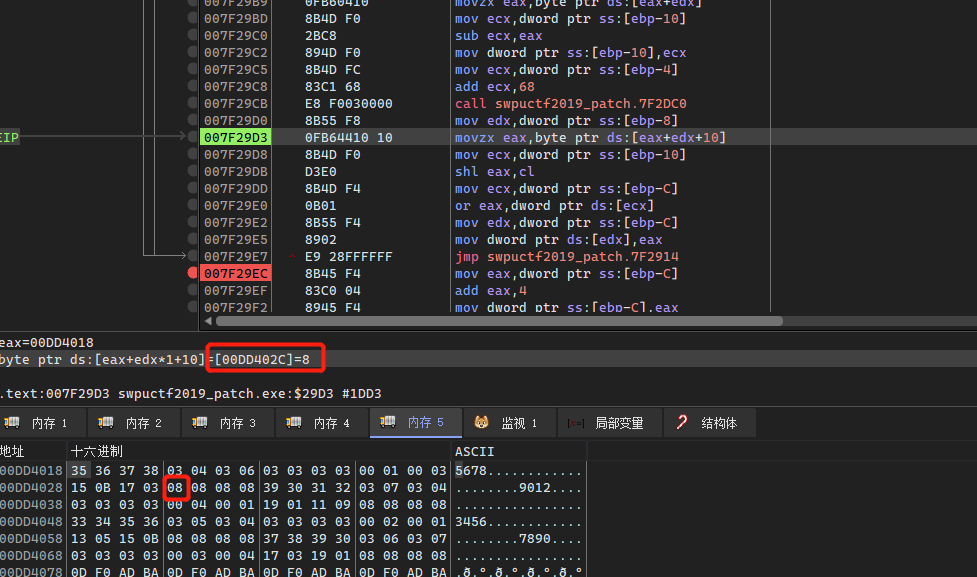
*v15 |= res2 << (v14 - res1)
最终的比较:
分析到这里,整个程序流程基本上就都了解了:
- 校验
flag格式 - 通过
-分割flag成5部分,对flag进行位移运算,对flag的每个字符都得到5个结果,将其存储到内存中 - 进行5次循环,每次循环处理4个字符,利用每个字符得到的5个结果继续进行移位和或运算,最终会生成两个结果,一个结果受字符影响,而另外一个结果是每个字符独立存在,不受其他字符的影响
- 将得到的结果与初始化中的两个字符串进行对比
exp
第一部分check_1左移进位位数,check_0计算右边0的个数,然后generate计算sub_402730后面的结果,并将三个结果作为list返回:
def check_1(c):
num = 0
while True:
c = c << 1
num += 1
if c & 0x100:
return num
def check_0(c): # 右边0的个数
num = 0
while True:
if c & 1:
return num
num += 1
c = c >> 1
def generate_0(c):
res1 = check_0(c) + check_1(c)
res2 = ((c << check_1(c)) & 0xff) >> res1
res3 = ((c >> (8 - check_1(c))) << check_1(c)) | ((c << (8 - check_0(c)) & 0xff) >> res1)
return [res1, res2, res3]
第二部分就是通过 03\"3 0 203\" $进行字符串排除,这里可以判断flag的范围应该是A-Za-z0-9,通过前面的分析知道每个字符运算的结果互相独立,但是这里可能存在重复的情况,所以先用set去重,然后对set中每个元素作为key,创建一个字典,如果check的结果为key则加入该key的value中,最后返回结果:
def check_part(c):
tmp = list(set(' 03\"3 0 203\" $ '))
tmp2 = check_0(c) | (16 * check_1(c))
for i in tmp:
if tmp2 == ord(i):
return i
return ''
def classify():
for_each = string.ascii_lowercase + string.ascii_uppercase + string.digits
second_part_res = ' 03\"3 0 203\" $ '
res = {}
d = dict.fromkeys(list(set(second_part_res)))
# print(d)
for i in list(set(second_part_res)):
d[i] = []
for i in for_each:
tmp = check_part(ord(i))
if tmp:
d[tmp].append(i)
return d
第三部分,test_1作为for循环中前四部分的计算,这里需要注意v14要代入并返回,经过8次运算后,将结果或成一个DWORD值,与first_part对应的DWORD进行对比,如果相等则返回此时循环的4个字符,这里是可以得到唯一值的,最终拼接得到flag:
def test_1(c, v14):
exam = {c: generate_0(ord(c))}
v14 = v14 - (8 - exam[c][0])
tmp = exam[c][1] << v14
return tmp, v14
def test_2(c, v14):
exam = {c: generate_0(ord(c))}
v14 = v14 - exam[c][0]
tmp = exam[c][2] << v14
return tmp, v14
def check_first_part(second_part, first_part):
for i in d[second_part[0]]:
for j in d[second_part[1]]:
for k in d[second_part[2]]:
for m in d[second_part[3]]:
v14 = 0x20
tmp, v14 = test_1(i, v14)
tmp2, v14 = test_1(j, v14)
tmp3, v14 = test_1(k, v14)
tmp4, v14 = test_1(m, v14)
tmp5, v14 = test_2(i, v14)
tmp6, v14 = test_2(j, v14)
tmp7, v14 = test_2(k, v14)
tmp8, v14 = test_2(m, v14)
tmp = tmp | tmp2 | tmp3 | tmp4 | tmp5 | tmp6 | tmp7 | tmp8
if tmp == first_part:
return i + j + k + m
d = classify()
s2 = ' 03\"3 0 203\" $ '
s = ['08', 'EA', '58', 'DE', '94', 'D0', '3B', 'BE', '88', 'D4', '32', 'B6', '14', '82', 'B7', 'AF', '14', '54', '7F', 'CF']
flag = 'swpuctf{'
for i in range(0, 5):
first_part = int(s[3 + 4 * i]+s[2 + 4 * i]+s[1 + 4 * i]+s[4 * i], 16)
second_part = s2[i*4:i*4+4]
res = check_first_part(second_part, first_part)
if i == 4:
flag += res
break
flag += res + '-'
flag += '}'
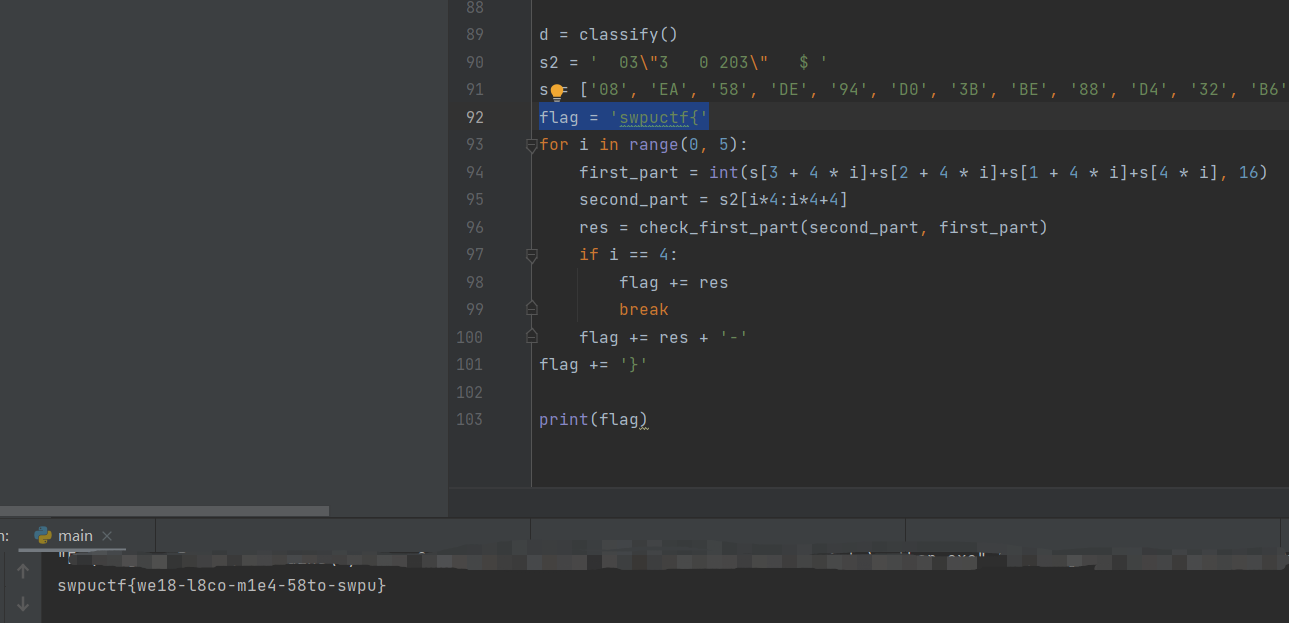
flag:
swpuctf{we18-l8co-m1e4-58to-swpu}
提交BUUCTF:

完整exp:
import string
def check_1(c): # 左移进位位数
num = 0
while True:
c = c << 1
num += 1
if c & 0x100:
return num
def check_0(c): # 右边0的个数
num = 0
while True:
if c & 1:
return num
num += 1
c = c >> 1
def generate_0(c):
res1 = check_0(c) + check_1(c)
res2 = ((c << check_1(c)) & 0xff) >> res1
res3 = ((c >> (8 - check_1(c))) << check_1(c)) | ((c << (8 - check_0(c)) & 0xff) >> res1)
return [res1, res2, res3]
def check_part(c):
tmp = list(set(' 03\"3 0 203\" $ '))
tmp2 = check_0(c) | (16 * check_1(c))
for i in tmp:
if tmp2 == ord(i):
return i
return ''
def classify():
for_each = string.ascii_lowercase + string.ascii_uppercase + string.digits
second_part_res = ' 03\"3 0 203\" $ '
d = dict.fromkeys(list(set(second_part_res)))
for i in list(set(second_part_res)):
d[i] = []
for i in for_each:
tmp = check_part(ord(i))
if tmp:
d[tmp].append(i)
return d
def test_1(c, v14):
exam = {c: generate_0(ord(c))}
v14 = v14 - (8 - exam[c][0])
tmp = exam[c][1] << v14
return tmp, v14
def test_2(c, v14):
exam = {c: generate_0(ord(c))}
v14 = v14 - exam[c][0]
tmp = exam[c][2] << v14
return tmp, v14
def calc_first_part(s):
v14 = 0x20
tmp, v14 = test_1(s[0], v14)
tmp2, v14 = test_1(s[1], v14)
tmp3, v14 = test_1(s[2], v14)
tmp4, v14 = test_1(s[3], v14)
tmp5, v14 = test_2(s[0], v14)
tmp6, v14 = test_2(s[1], v14)
tmp7, v14 = test_2(s[2], v14)
tmp8, v14 = test_2(s[3], v14)
return tmp | tmp2 | tmp3 | tmp4 | tmp5 | tmp6 | tmp7 | tmp8
def check_first_part(second_part, first_part):
for i in d[second_part[0]]:
for j in d[second_part[1]]:
for k in d[second_part[2]]:
for m in d[second_part[3]]:
tmp = i + j + k + m
if calc_first_part(tmp) == first_part:
return tmp
d = classify()
s2 = ' 03\"3 0 203\" $ '
s = ['08', 'EA', '58', 'DE', '94', 'D0', '3B', 'BE', '88', 'D4', '32', 'B6', '14', '82', 'B7', 'AF', '14', '54', '7F', 'CF']
flag = 'swpuctf{'
for i in range(0, 5):
first_part = int(s[3 + 4 * i]+s[2 + 4 * i]+s[1 + 4 * i]+s[4 * i], 16)
second_part = s2[i*4:i*4+4]
res = check_first_part(second_part, first_part)
if i == 4:
flag += res
break
flag += res + '-'
flag += '}'
print(flag)
优化:
import string
class SwpuctfBabyre():
def __init__(self):
self.s2 = ' 03\"3 0 203\" $ '
self.s = ['08', 'EA', '58', 'DE', '94', 'D0', '3B', 'BE', '88', 'D4', '32', 'B6', '14', '82', 'B7', 'AF', '14', '54',
'7F', 'CF']
self.flag = 'swpuctf{'
self.d = dict.fromkeys(list(set(self.s2)))
self.v14 = 0x20
for i in list(set(self.s2)):
self.d[i] = []
def check_1(self, c): # 左移进位位数
num = 0
while True:
c = c << 1
num += 1
if c & 0x100:
return num
def check_0(self, c): # 右边0的个数
num = 0
while True:
if c & 1:
return num
num += 1
c = c >> 1
def generate_0(self, c):
res1 = self.check_0(c) + self.check_1(c)
res2 = ((c << self.check_1(c)) & 0xff) >> res1
res3 = ((c >> (8 - self.check_1(c))) << self.check_1(c)) | ((c << (8 - self.check_0(c)) & 0xff) >> res1)
return [res1, res2, res3]
def check_part(self, c):
tmp = list(set(self.s2))
tmp2 = self.check_0(c) | (16 * self.check_1(c))
for i in tmp:
if tmp2 == ord(i):
return i
return ''
def classify(self):
for_each = string.ascii_lowercase + string.ascii_uppercase + string.digits
for i in for_each:
tmp = self.check_part(ord(i))
if tmp:
self.d[tmp].append(i)
def test_1(self, c):
exam = {c: self.generate_0(ord(c))}
self.v14 = self.v14 - (8 - exam[c][0])
tmp = exam[c][1] << self.v14
return tmp
def test_2(self, c):
exam = {c: self.generate_0(ord(c))}
self.v14 = self.v14 - exam[c][0]
tmp = exam[c][2] << self.v14
return tmp
def calc_first_part(self, s):
self.v14 = 0x20
tmp = 0
for i in s:
tmp |= self.test_1(i)
for i in s:
tmp |= self.test_2(i)
return tmp
def check_first_part(self, second_part, first_part):
for i in self.d[second_part[0]]:
for j in self.d[second_part[1]]:
for k in self.d[second_part[2]]:
for m in self.d[second_part[3]]:
tmp = i + j + k + m
if self.calc_first_part(tmp) == first_part:
return tmp
def run(self):
self.classify()
for i in range(0, 5):
first_part = int(self.s[3 + 4 * i]+self.s[2 + 4 * i]+self.s[1 + 4 * i]+self.s[4 * i], 16)
second_part = self.s2[i*4:i*4+4]
res = self.check_first_part(second_part, first_part)
if i == 4:
self.flag += res
break
self.flag += res + '-'
self.flag += '}'
print(self.flag)
if __name__ == '__main__':
swpuctf = SwpuctfBabyre()
swpuctf.run()