推荐算法有哪些?
37 个回答

本文调研了推荐系统里的7种经典推荐算法,按原理分析和场景应用,以及适合解决的问题给大家做了梳理。
(点击头像关注我们账号,别错过更多阿里工程师一线技术干货)
—————————————————————————————————————
前言
个性化推荐,是指通过分析、挖掘用户行为,发现用户的个性化需求与兴趣特点,将用户可能感兴趣的信息或商品推荐给用户。本文调研了推荐系统里的经典推荐算法,结合论文及应用进行分析、归纳并总结成文,既是自己的思考过程,也可当做以后的翻阅手册。俗话说学而时习之,人的认识过程是呈螺旋式上升的,特别是理论应用到实践的过程,理论是实践的基础,实践能反过来指导人对理论的认识,我相信在将下文所述的算法应用到业务中的实践过程也将刷新我在总结此文时的认识。
个性化推荐系统是一项系统工程,为便于聚焦描述,本文不涉及模型的训练及部署等工程问题,仅对推荐算法原理进行分析和其解决的问题进行总结。
为方便分析,本文取大家购物时常遇到的商品推荐模型的某些特征进行举例:
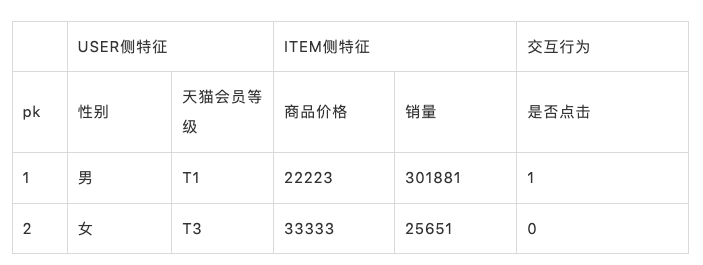

特征可简单分为两类:
- 连续特征。如商品价格/销量时长
- 类别特征。如性别/天猫会员等级
对于连续的数值特征,可直接在模型中作为数值参与计算(大部分情况下需要进行归一化等处理)。而对于类别特征,一般是不能直接作为数值参与计算的,通常将其进行Hash散列编码或者one-hot编码。
以one-hot编码为例,将以上训练数据进行预处理。


预处理之后,可以看到所有的数据已经进行的数值化,可以进行数学运算了。
接下来将介绍各算法模型是如何利用这些数据进行学习的。
LR
▐ 算法原理
逻辑回归LR(Logistic Regression)模型作为经典的机器学习分类模型,以其可解释性强、实现简单、线上高效等优点在线上应用中被大量使用。逻辑回归模型主要有两部分构成:
- 线性回归
- 逻辑函数
在机器学习中,线性回归模型可记为:
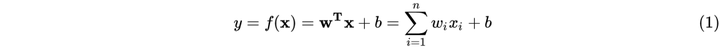

而逻辑函数使用的为sigmoid函数:
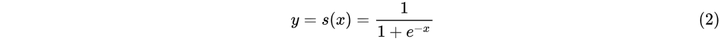

由(1)和(2)可推出LR模型的数学表达式为
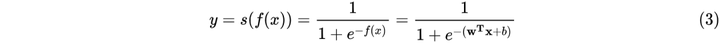

在线性回归模型(1)中,
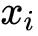
是具体的某一个特征值,
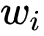
是该特征值的权重,是模型的输出。该公式可以直白的解释为模型的输出结果是由输入进行线性加权求和得到的。而逻辑函数(2)的作用是将线性回归模型的输出映射到[0,1],输出一个概率值。商品推荐的场景中如用户对某个item进行点击记为1,未点击记为0。
▐ 解决的问题
LR是一个基本的回归模型,可以对输入进行一些线性运算得到一个预测的输出值。预测值可以是用户点击某个商品的概率,也可以是用户下单的概率,其含义具体业务具体分析。
FM
▐ 算法原理
FM(Factorization Machine)。LR作为一个基础的回归模型,主要原理是通过对各个特征进行线性加权得到预测值,但是其并没有考虑组合特征对模型的影响,比如一名单身女性在晚上观看李佳琦直播概率显然是大于一名妈妈的,这里面包含的组合特征单身女性-晚上在LR中就体现不到。因此相比LR仅对一阶特征进行建模,FM引入了二阶特征,增强了模型的学习能力和表达能力。FM的数学表达式如下:
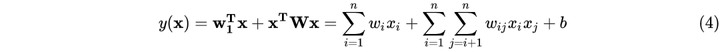

如果FM仅仅是在模型的表达式上加入了二阶特征,它的应用绝不会这么广泛,只从式(4)中就可以看出表达式上其实相对于LR的改进是很简单的:在模型中引入输入特征两两组合进行乘积就行了。但是这样会引入一个很大的问题:参数的数目直接从个爆炸增长为
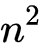
个,这对于特征维度动辄上千上万数量级的推荐系统来说是断然不能接受的。
面对这么大的参数矩阵很容易想到将其进行矩阵分解,我们首先观察一下参数矩阵
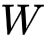
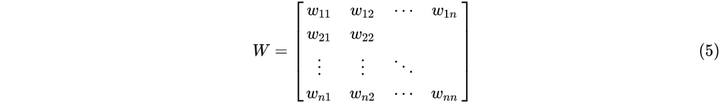

可以看到参数矩阵

是实对称矩阵,可以想到正定矩阵是可以很优雅的进行分解的:
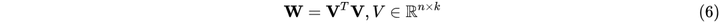

特别地,在稀疏矩阵中
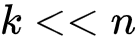
的情况下,便可满足式(6)的近似相等。
设
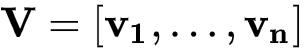

,则式(4)中的模型参数可表示为
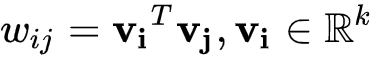
。因此限定参数矩阵为正定矩阵的情况下,FM的二阶特征的表达式可推导如下:
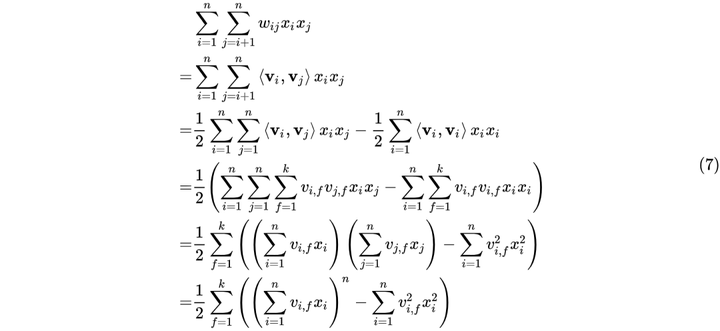

对比式(6)和式(7)可知,FM的计算复杂度由
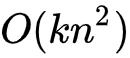
降至

,而k的值又是一个可根据业务情况硬编码的值,式(7)的推导使得FM的时间复杂度降至线性复杂度,无论是对于模型的离线训练还是在线推理均使得二阶特征组合成为可能。
▐ 解决的问题
FM通过引入二阶特征实现了模型学习能力及表达能力的提升,并且利用正定矩阵和稀疏矩阵的性质将二阶特征的计算降低至线性复杂度,也因此成为工业界常用的特征工程算法。
FFM
▐ 算法原理
FFM(Field-aware Factorization Machine)。从名字上看,相较于FM, FFM多了一个F,在实现上也是如此。
FFM的数学表达式如下:
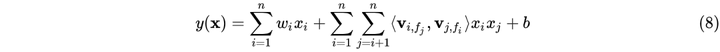

从式(8)可以看出FFM相比于FM的不同点在于二阶特征组合的系数上,FFM的权重矩阵比FM多了一维。其算法思想是这样的:以前言中的商品推荐的训练数据举例,在进行one-hot编码时,我们将不同的字段的特征进行编码然后拉平送进模型进行训来,比如字段天猫会员等级T1和天猫会员等级T3这俩字段被独立为两个独立的特征。然而实际情况却是这俩字段其实是对同一个字段天猫会员等级的不同描述。因此在FFM中引入了field的概念:每一维的特征都有对应的field,在进行二阶特征组合时某一维特征对于不同field的特征其所对应的隐向量是不同的。假设所有特征共包含f个filed,则FFM权重矩阵


,相比于FM的权重矩阵
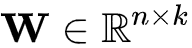
,多出的维便对应着FFM中引入的field的数目。
需要说明的是,FM可以看做是FFM的特例:所有特征属于同一个field。
▐ 解决的问题
引入field更精准刻画了各维特征之间的关系,通过增大隐向量的数目增强了模型的表达能力。但是由于其隐向量与field有关,其相关计算无法像FM那样化简,在面对特征维度n比较大的情况下,其计算性能容易成为系统瓶颈。
WDL
▐ 算法原理
WDL(Wide & Deep Learning)。其核心思想是结合线性模型(如上文的LR)的记忆能力和DNN模型的泛化能力来提升模型的整体能力。
其网络结构图如下:
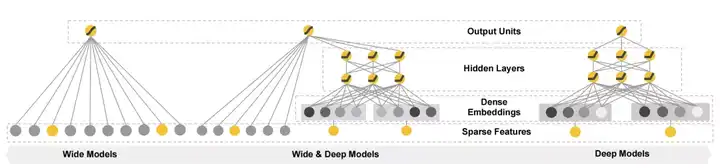

其中包括
- wide部分:wide部分是普通的线性模型,其表达式可参见式(1)
- deep部分:deep部分由一个3层的神经网络组成。其输入是对原始的稀疏特征(如ID类特征)进行一次embedding后的结果。每一层的公式如下:
- 输出:输出部分将线性模型(Wide)和DNN(Deep)模型的输出结果进行加和作为整个模型的loss进行反向传播来完成联合训练。
▐ 解决的问题
结合了线性模型对一阶特征和和深度模型对高阶特征的学习能力来整体提高模型的表达能力。
DeepFM
▐算法原理
WDL可以看做是LR+DNN,那么DeepFM就可以看做是FM+DNN。相比于WDL做出的改进,DeepFM主要是将WDL中Wide模块由LR替换为了FM。
其网络结构如图所示:
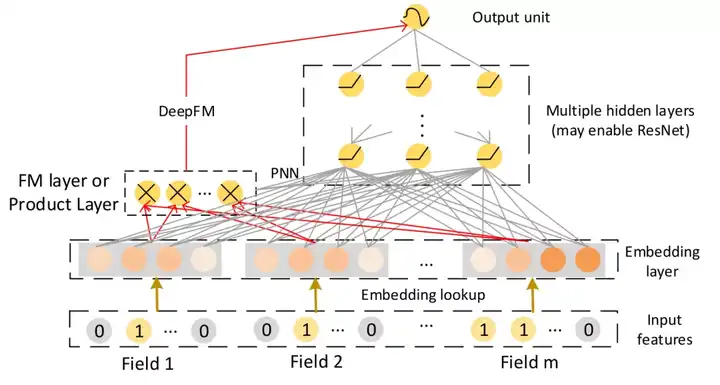

可以看到相对于WDL其做了以下改进:
- 引入FM结构代替LR。完成对一阶二阶特征的学习 避免了WDL中人工特征工程过程。见式(4)。
- FM和DNN共享Embedding层。减少了额外的计算开销。
▐解决的问题
在减去人工特征工程的前提下,通过Wide部分和Deep部分共享Embedding,可以提高模型的训练速度和模型的特征学习能力。
DcN
▐算法原理
DCN(Deep & Cross Network)如其名字中cross所示,其主要完成了完全去手工特征交叉的工作。
其中代替DeepFM中FM模块的核心Cross Network网络结构如下:
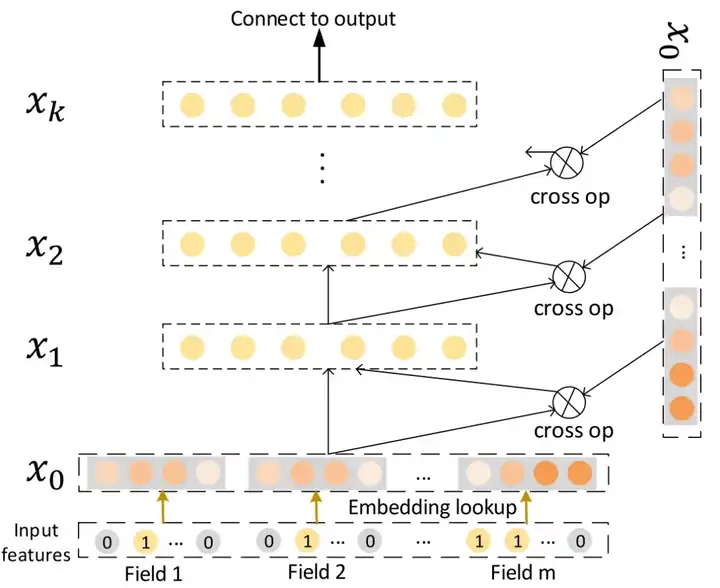

其中:
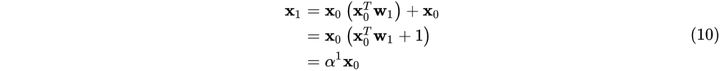

进而可推出
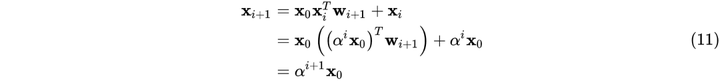

可以看出Cross Network中每一层的输出都是由

与某一标量进行相乘的结果。因此:
- 每层的输出和
同维
- 由于标量和

是相关的,因此第k层的输出包含了
的1到k+1阶特征。
▐解决的问题
完全舍弃了人工特征工程过程,并且可以显示指定特征交叉阶数。
xDeepFM
▐算法原理
xDeepFM(eXtreme Deep Factorization Machine)。从名字上可以看出,xDeepFM是是对于DeepFM的改进,但是实际上xDeepFM是对DCN的改进。DCN 的Cross层在Embedding层后,可以自动构造任意阶高阶特征,但是它是bit-wise的,与bit-wise对应的是vector-wise。现举例分析如下:例如,性别对应嵌入向量<a1,a2,a3>,天猫会员等级对应嵌入向量<b1,b2,b3>,在DCN的Cross网络中,向量<a1,a2,a3>,<b1,b2,b3>会拼接为<a1,a2,a3,b1,b2,b3>作为输入,在进行cross的时候a1可能事实上属于同一个field的a2进行cross。因此称DCN以嵌入向量中的单个bit为最细粒度,即bit-wise。而在FM中,特征的交叉是以该维特征对应的向量为最细粒度进行交叉来学习相关性的,即vector-wise。而xDeepFM的动机,正是将FM的vector-wise的思想引入Cross部分。这一点其实特别像one-hot编码的情况下FM到FFM的演进。
xDeepFM中,进行vector-wise特征交叉的结构如下:
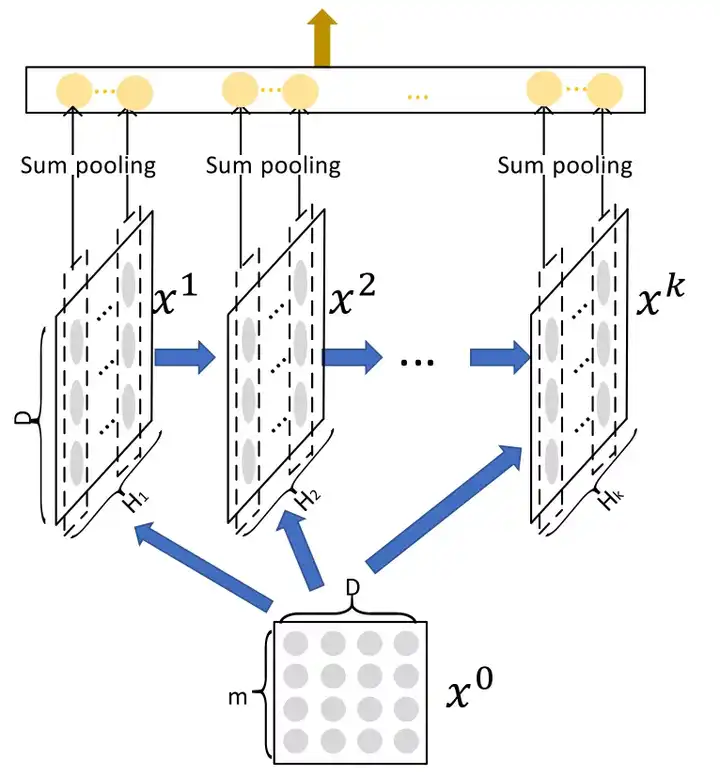

对于每一层的输出
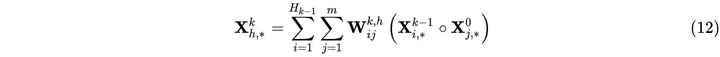

其中
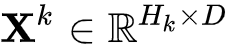

代表了第层的输出
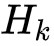
代表了第k层输出的vector个数
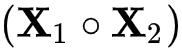
表示两向量对应元素两两相乘,如


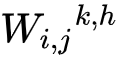
表示第层第个向量的向量的权重矩阵
至此,xDeepFM便实现了vector-wise的特征交叉过程。相比于DCN,其第 的输出仅包含了k+1阶特征。因此,其需要将每层的输出进行sum-pooling后DNN的输出加和到一起作为loss进行反向传播来完成联合训练。
▐ 解决的问题
提出了一种vector-wise的高阶特征交叉方式。
小结
本文以解决问题的思路介绍了推荐系统里的经典算法演进过程,可以看到每种算法的出现都是为了解决某种特定的问题。学术上评价一个算法的好坏大都在于其精度,而在工业界中,更看重的是一个算法精度与性能的trade-off。比如2013年微软在NLP领域提出的双塔模型,被应用到推荐系统后经久不衰,到现在仍然在各大公司推荐系统里发光光热,究其原因:双塔模型上线有多方便/跑的有多快,谁用谁知道...
个性化推荐系统算法的演进相比于CV(计算机视觉)和NLP(自然语言处理)来说并没那么快,这一点从顶会论文数目上可窥一斑。究其原因我个人认为是其所应用的场景所限,个性化推荐本质上是一个人与物的匹配过程,所以使用这套系统的前提是应用场景下要有大量的人和大量的物,场景强绑定的特性提高了其研究门槛。而CV和NLP更像是一个个的基础组件,几十人甚至几人的团队就可在CV或者NLP的某个子任务上做出开创性工作然后将其推广至各个不同的应用场景下。比如CV里鼎鼎大名的YOLO系列,其作者凭一人之力一次次帮助各相关厂商主动升级各家的应用SDK...
(本篇内容作者:阿里巴巴淘系技术部 羊灵)
——————————————————————————————————————————
阿里巴巴集团淘系技术部官方账号。淘系技术部是阿里巴巴新零售技术的王牌军,支撑淘宝、天猫核心电商以及淘宝直播、闲鱼、阿里汽车、阿里房产等创新业务,服务9亿用户,赋能各行业1000万商家。我们打造了全球领先的线上新零售技术平台,并作为核心技术团队保障了13次双十一购物狂欢节的成功。详情可查看我们官网:阿里巴巴淘系技术部官方网站。
点击下方主页关注我们,你将收获更多来自阿里一线工程师的技术实战技巧&成长经历心得。另,不定期更新最新岗位招聘信息和简历内推通道,欢迎各位以最短路径加入我们。

推荐算法大致可以分为三类:基于内容的推荐算法、协同过滤推荐算法和基于知识的推荐算法。
基于内容的推荐算法,原理是用户喜欢和自己关注过的Item在内容上类似的Item,比如你看了哈利波特I,基于内容的推荐算法发现哈利波特II-VI,与你以前观看的在内容上面(共有很多关键词)有很大关联性,就把后者推荐给你,这种方法可以避免Item的冷启动问题(冷启动:如果一个Item从没有被关注过,其他推荐算法则很少会去推荐,但是基于内容的推荐算法可以分析Item之间的关系,实现推荐),弊端在于推荐的Item可能会重复,典型的就是新闻推荐,如果你看了一则关于MH370的新闻,很可能推荐的新闻和你浏览过的,内容一致;另外一个弊端则是对于一些多媒体的推荐(比如音乐、电影、图片等)由于很难提内容特征,则很难进行推荐,一种解决方式则是人工给这些Item打标签。
协同过滤算法,原理是用户喜欢那些具有相似兴趣的用户喜欢过的商品,比如你的朋友喜欢电影哈利波特I,那么就会推荐给你,这是最简单的基于用户的协同过滤算法(user-based collaboratIve filtering),还有一种是基于Item的协同过滤算法(item-based collaborative filtering),这两种方法都是将用户的所有数据读入到内存中进行运算的,因此成为Memory-based Collaborative Filtering,另一种则是Model-based collaborative filtering,包括Aspect Model,pLSA,LDA,聚类,SVD,Matrix Factorization等,这种方法训练过程比较长,但是训练完成后,推荐过程比较快。
最后一种方法是基于知识的推荐算法,也有人将这种方法归为基于内容的推荐,这种方法比较典型的是构建领域本体,或者是建立一定的规则,进行推荐。
混合推荐算法,则会融合以上方法,以加权或者串联、并联等方式尽心融合。
当然,推荐系统还包括很多方法,其实机器学习或者数据挖掘里面的方法,很多都可以应用在推荐系统中,比如说LR、GBDT、RF(这三种方法在一些电商推荐里面经常用到),社交网络里面的图结构等,都可以说是推荐方法。