『看看论文』是一系列分析计算机和软件工程领域论文的文章,我们在这个系列的每一篇文章中都会阅读一篇来自 OSDI、SOSP 等顶会中的论文,这里不会事无巨细地介绍所有的细节,而是会筛选论文中的关键内容,如果你对相关的论文非常感兴趣,可以直接点击链接阅读原文。
本文要介绍的是 2018 年 OSDI 期刊中的论文 —— Maelstrom: Mitigating Datacenter-level Disasters by Draining Interdependent Traffic Safely and Efficiently1,Facebook 通过流量管理系统 Maelstrom 转发数据中心的流量,在出现一个或者多个数据中心故障时,减轻故障对业务造成的影响。
很多工程师可能认为数据中心级别的故障并不常见,但是实际上这也是经常发生的问题,飓风在美国是比较常见的自然灾害,因为飓风导致的断电和洪水就会经常对数据中心造成影响2,而人为因素,例如:光缆断裂、软件故障和错误配置都会影响整个数据中心3。作为从 2014 年就已经在生产环境使用的系统,到 2018 年为止,Maelstrom 已经帮助 Facebook 缓解了 100 多次数据中心故障带来的损失。
既然数据中心宕机并是可能发生的事件,那么作为工程师,如何减少类似突发事件对线上服务和业务的影响成为了保障可用性的必须要做的事情。Maelstrom 论文介绍了很多具体的实践经验,例如:定期测试、Runbook 设计,然而这些都不是作者关心的内容,我们在这里重点介绍 Maelstrom 对流量的分类以及不同流量的排出过程。
数据中心作为流量调度的维度,它有着非常粗的粒度,如果我们直接将数据中心的流量通过配置全部转发的其他数据中心可能会出现很多问题,所以在排出数据中心的流量时,需要根据服务内部的依赖和资源限制设计不同的策略。为了区分数据中心流量的特性,Maelstrom 将数据中心的流量分成四类:
图 1 - 流量种类
- 无状态流量(Stateless):绝大多数的网络流量都是无状态的,我们可以非常容易地将这些流量转发到其他的数据中心;
- 粘性流量(Sticky):为了提升用户体验,在某些场景下系统会为每个用户会由特定的机器处理以维持用户会话,对于这种流量,我们可以将新的粘性流量转发到其他数据中心并强制断开已建立的会话触发客户端的重连;
- 复制流量(Replication):当发生数据中心级别故障时,我们可能需要修改或者管理存储系统的复制流量,我们可能需要在其他数据中心创建副本来处理读请求,而副本的创建需要占用数据中心内部或者跨数据中心的网络资源;
- 有状态流量(Stateful):主从复制的系统在主节点发生故障时,我们需要将主节点的状态拷贝至健康数据中心中的从节点,并将从节点进程成主节点以服务请求;
根据流量的特性不同,我们需要使用不同的方法进行转发,接下来我们将分别介绍 Maelstrom 排出不同类型流量的过程以及所需要的时间。
无状态流量
无状态流量是四种类型流量中转发过程最简单的,为了保证整个系统的稳定,在排出数据中心流量的过程中,我们引入排出乘数(Drain Multiplier)并引入了几个不同的阶段防止流量转移的太过迅速影响其他数据中心的负载:
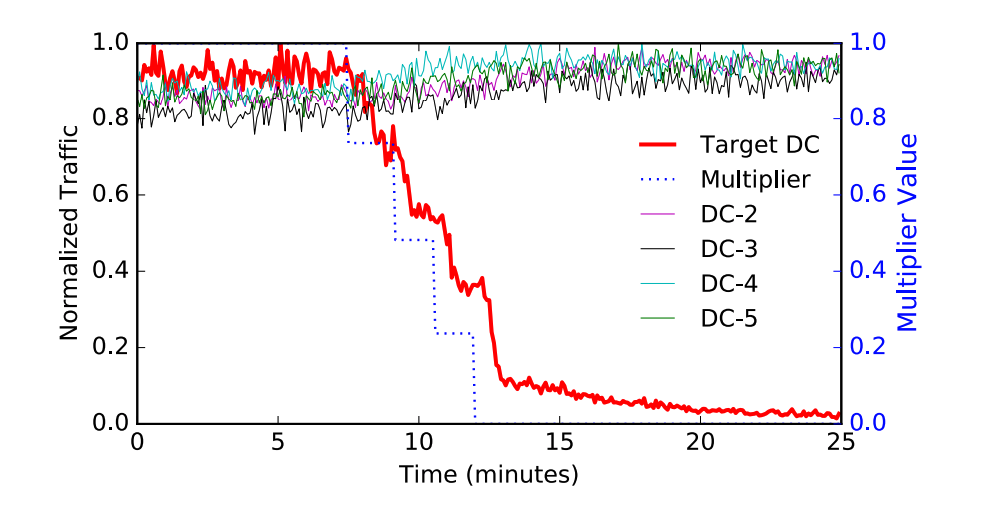
图 2 - 排出无状态流量
如上图所示,Maelstrom 处理无状态流量的速度非常快,在不影响用户和服务的情况下,它能够在 10 分钟以内排出整个数据中心绝大多数的流量,Facebook 会使用 10min 作为基准线衡量在灾难发生时转发请求的速度。
粘性流量
与无状态流量相比,排出粘性流量会稍显复杂,Maelstrom 不仅会修改边缘的路由器将新的请求转发到其他数据中心,还会通过重启容器任务销毁本地建立的会话:
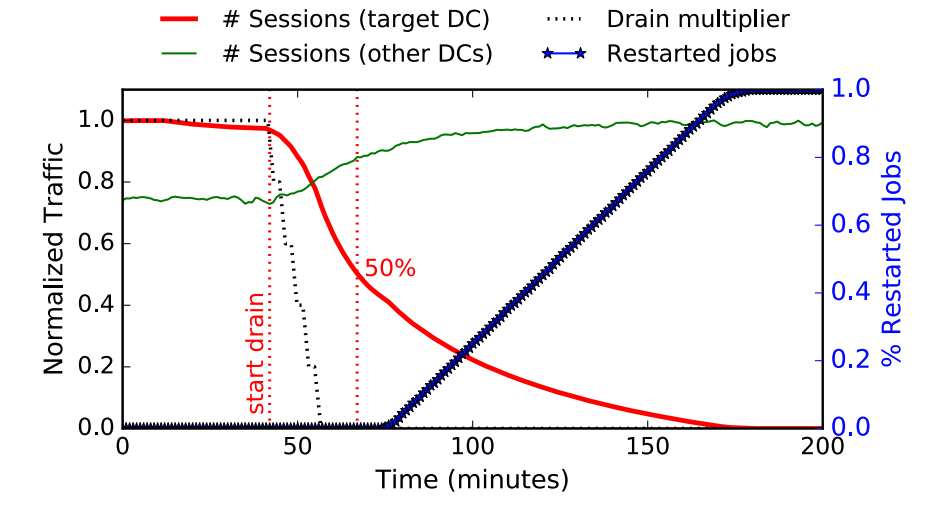
图 3 - 排出粘性流量
如上图所示,Maelstrom 在 42 分钟开始修改边缘路由的权重重定向会话请求并在 75 分钟开始重启容器任务销毁本地会话,为了降低大批量重启对其他数据中心造成的影响,我们会降低容器任务的重启速度,所以这里大概需要 25 分钟的时间才可以将 50% 的粘性流量转发到其他数据中心。
复制流量
数据存储服务的复制流量可以通过配置直接关闭,我们可以将新的请求直接指向其他数据中心的只读副本,如下图所示,你可以看到当我们关闭数据中心的复制后,复制流量带来的网络请求很快就归零了,不过数据存储服务的恢复过程却相对比较复杂:
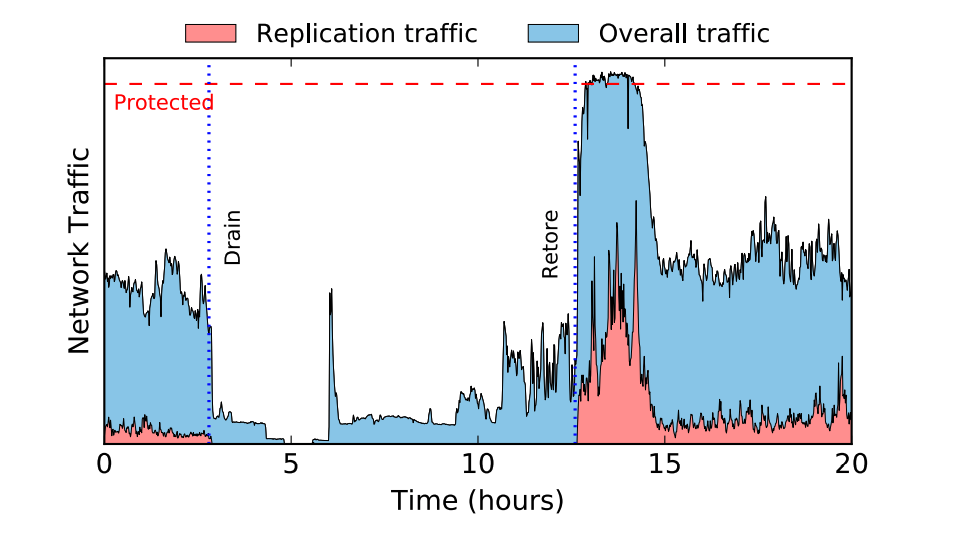
图 4 - 排出和恢复复制流量
因为在关闭复制期间,整个系统仍然要处理外部的请求,所以其他数据中心的存储服务中仍然有数据的增删改操作,当重新启动数据存储的拷贝时,过期的副本会占用 10 倍的网络带宽追赶主节点的状态,这可能会造成骨干网和数据中心网络的拥堵影响其他的服务;从上图中能看到复制流量重启后对整体网络流量造成的影响,我们可以引入限制不同流量的带宽减少突发流量带来的事故。
有状态流量
排出有状态流量的过程是最复杂的,如下图所示,Ads、Aggregator-leaf 和 Classification 服务都会将数据存储在多租户的有状态存储中,当灾难发生时,Maelstrom 将数据中心外的节点晋升为主节点,然后将流量转发到该节点上:
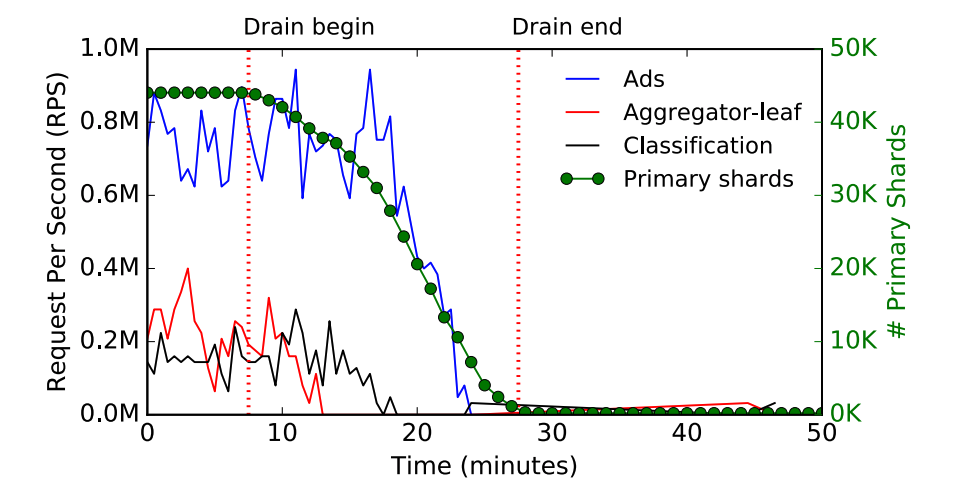
图 5 - 排出有状态流量
因为不同服务的分片都是各自独立的,所以我们可以并行地晋升并转发不同分片的写操作,从数据中心转发有状态流量是一件相对比较困难的事情,我们大概需要 18 分钟才可以完成这一过程。
总结
缓解数据中心级别的故障是一个非常大的话题,但是 Maelstrom 给出的解决方案看起来却异常的简单 —— 将数据中心的流量转发到其他的数据中心。不过这个方案涉及了相当多的组件并面临各种潜在的问题,在真正实施的过程中会遇到很多没有考虑到的细节,需要很多工程上的经验,将数据中心的流量进行分类并按照特性进行处理就是一个非常值得学习和借鉴的手段,我们在处理类似问题时,也应该学会先将大问题分解成小问题并依次解决。
推荐阅读
Kaushik Veeraraghavan, Justin Meza, Scott Michelson, Sankaralingam Panneerselvam, Alex Gyori, David Chou, Sonia Margulis, Daniel Obenshain, Shruti Padmanabha, Ashish Shah, Yee Jiun Song, and Tianyin Xu. 2018. Maelstrom: mitigating datacenter-level disasters by draining interdependent traffic safely and efficiently. In Proceedings of the 13th USENIX conference on Operating Systems Design and Implementation (OSDI'18). USENIX Association, USA, 373–389. ↩︎
KRISHNAN, K. Weathering the Unexpected. Communications of the ACM (CACM) 55, 11 (Nov. 2012), 48–52. ↩︎
GUNAWI, H. S., HAO, M., LEESATAPORNWONGSA, T., PATANA-ANAKE, T., DO, T., ADITYATAMA, J., ELIAZAR, K. J., LAKSONO, A., LUKMAN, J. F., MARTIN, V., AND SATRIA, A. D. What Bugs Live in the Cloud? A Study of 3000+ Issues in Cloud Systems. In Proceedings of the 5th ACM Symposium on Cloud Computing (SoCC’14) (Seattle, WA, USA, Nov. 2014). ↩︎

转载申请

本作品采用知识共享署名 4.0 国际许可协议进行许可,转载时请注明原文链接,图片在使用时请保留全部内容,可适当缩放并在引用处附上图片所在的文章链接。
Go 语言设计与实现
各位读者朋友,很高兴大家通过本博客学习 Go 语言,感谢一路相伴! 《Go语言设计与实现》 的纸质版图书已经上架京东,本书目前已经四印,印数超过 10,000 册,有需要的朋友请点击 链接 或者下面的图片购买。
